Indeks Lucene
Podstawą wyszukiwania w systemie Mercury DB jest Indeks Lucene. W niniejszy artykule przedstawione zostaną zasady tworzenia nazewnictwa pól, które są podstawą do realizacji zapytań wyszukiwania. Zaprezentowany zostanie również podział pól ze względu na ich rodzaj, kategorię (podział ze względu na pochodzenie pola) oraz sposób wyszukiwania (podział ze względu na typ pola). Indeks Lucene jest bardzo elastyczny i pozwala na tworzenie wyspecjalizowanych zapytań, które mogą być dostosowane do różnych potrzeb użytkowników. Warto zaznaczyć, że Indeks Lucene jest wykorzystywany nie tylko w systemie Mercury DB, ale również w wielu innych systemach bazodanowych i wyszukiwarkach internetowych.
Ze względu na rozwój systemu i coraz to nowe wymagania, nazewnictwo pól indeksu Lucene zostało opracowane w dwóch modelach: Model 2.0 oraz Model 3.0. Wybór modelu nazewnictwa pól definiuje się w parametrach konfiguracyjnych systemu. O tym jaki model nazewnictwa jest wykorzystywany definiuje parametr mercury.lucene.model.version konfiguracji systemu przechowywany w pliku mercury.properties. Parametr przyjmuje jedną z dwóch wartości: 2 lub 3.
Struktura dokumentu indeksu
Dokument indeksu Lucene w systemie Mercury DB oparty jest o dane składowane w relacyjnej bazie danych.
Model indeksu Lucene jest definiowany w trakcie procesu instalacji systemu Mercury DB. Warto zaznaczyć, że model ten jest ściśle związany z architekturą systemu i jego funkcjonalnościami. W przypadku zmiany modelu indeksu, konieczna jest przebudowa indeksu Lucene oraz wprowadzenia odpowiednich zmian w aplikacjach realizujących zadania wyszukiwania danych
Poniższy diagram encji prezentuje poszczególne elementy dokumentu, które składowane są w relacyjnej bazie danych. Każda encja jest reprezentowana przez odpowiednie pola w dokumencie indeksu Lucene (zobacz Nazwy pól stałych/predefiniowanych).
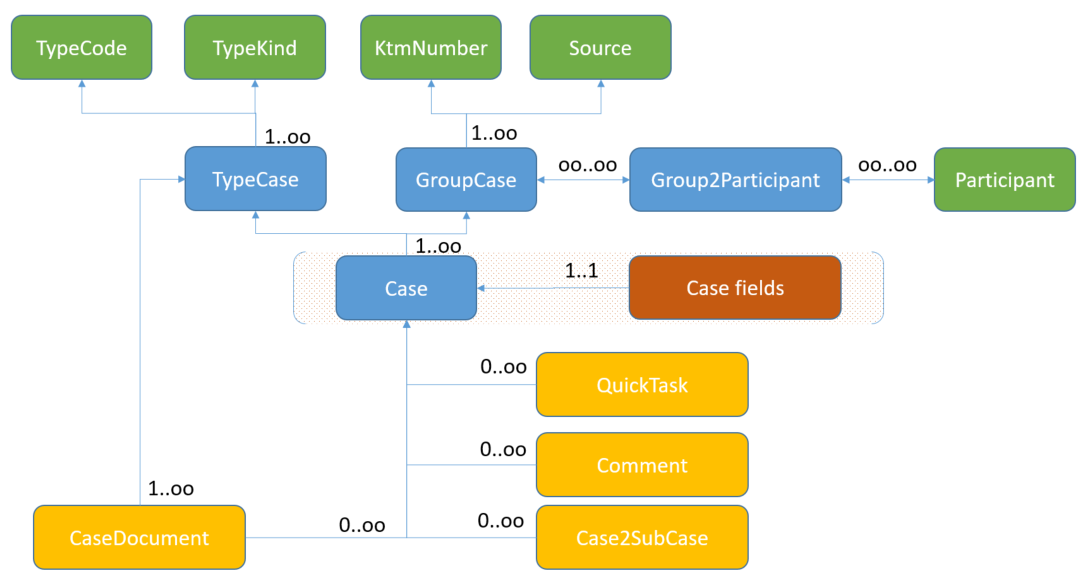
Przechowywanie dokumentu w indeksie
Architektura przechowywanych danych w relacyjnej bazie danych sprawia, że jednemu dokumentowi indeksu Lucene odpowiada jeden wpis (wiersz) w tabeli reprezentującej encję Case. Charakter obiektowości przechowywanych danych wprowadza konieczność budowania powiązań pomiędzy zaindeksowanymi dokumentami. Aby dokładniej to wyjaśnić przeanalizujmy poniższy przypadek obiektu przykładowej definicji sprawy złożonej o nazwie EliAddress:

Mamy sprawę nadrzędną (EliClient, rodzic) oraz sprawę podrzędną (EliAddress, dziecko). Ich dane przechowywane są jako oddzielne wiersze w tabeli. Powiązanie, które pomiędzy nimi istnieje (pole clientAddress w sprawie nadrzędnej), w relacyjnej bazie zapisane jest jako wiersz encji Case2SubCase. Aby odzwierciedlić to powiązanie w zaindeksowanych dokumentach, silnik indeksowania HgDB dodaje odpowiednie pola zarówno do dokumentu sprawy nadrzędnej jak i podrzędnej.
Do dokumentu sprawy nadrzędnej (EliClient, rodzic) dodane zostanie pole o nazwie utworzonej wg reguły: <nazwa_pola>_<nawa_pola_z_id_sprawy>, czyli w naszym przypadku, używając nazewnictwa modelu 3.0, clientAddress_mrc_Case_id z wartością odpowiadającą identyfikatorowi sprawy podrzędnej. Powstaje pole będące odpowiednikiem klucza obcego w relacyjnej bazie danych. To pozwoli silnikowi Mercury DB (HgDB) 3.0 zrealizowanie odpowiedniego zapytania wiążącego, wyszukanie sprawy podrzędnej o odpowiednim identyfikatorze.
Do dokumentu sprawy podrzędnej (EliAddress, dziecko) zostaną dodane dwa pola wielowartościowe:
parentFields- pole z nazwą pola wiążącego, do którego z w naszym przypadku zostanie dodana wartośćclientAddressparentTypes- pole z nazwą typu sprawy nadrzędnej, do którego z w naszym przypadku zostanie dodana wartośćEliClient
To pozwoli optymalizację zapytań pozwalających na znalezienie sprawy nadrzędnej.
Zasady budowania nazw pól
W dokumencie indeksu Lucene możemy wyróżnić dwa główne rodzaje pól: pola stałe/predefiniowane i pola dynamiczne. Dla każdego rodzaju zostały stworzone inne zasady tworzenia nazewnictwa pól indeksu Lucene.
Pola stałe/predefiniowane
Pola stałe/predefiniowane to pola, które są zdefiniowane w modelu indeksu Lucene i nie mogą być modyfikowane przez użytkowników. Są to pola, które są niezbędne do prawidłowego działania systemu i są wykorzystywane do przechowywania podstawowych informacji o dokumentach. Przykłady takich pól to: mrc_Case_id, mrc_Case_type, mrc_Case_status.
Został wprowadzony podział pól, ze względu na ich pochodzenie w postaci kategorii pól. Kategorie reprezentują encje, a ich nazwy to nazwy encji, w których występują pola.
Aby odróżnić ten rodzaj pól od pól obiektów spraw (pól dynamicznych), w Modelu 3.0 nazewnictwo dla wszystkich pól stałych, zostało opatrzone dodatkowym prefiksem mrc_.
Poniżej przedstawiono zasady nazewnictwa pól ze względu na ich przydział do kategorii:
- TypeCode - pola reprezentujące dane dotyczące definicji kodu typu sprawy albo typu dokumentu powiązanego ze sprawą. W zależności od wykorzystywanego modelu nazewnictwa w systemie do podstawowych nazw pól encji dodawany jest prefiks:
- dla typów obiektów spraw to
typeTypeCodedla modelu 2.0 oraz typeCode dla modelu 3.0. Przykład nazwy pola dla modelu 3.0:mrc_typeCodeValue. - dla typów obiektów dokumentów to
c2docTypeTypeCodedla modelu 2.0 orazc2docTypeCodedla modelu 3.0.
- dla typów obiektów spraw to
- TypeKind - pola reprezentujące dane dotyczące rodzaju typu sprawy albo powiązanego ze sprawą dokumentu. W zależności od wykorzystywanego modelu nazewnictwa w systemie do podstawowych nazw pól encji dodawany jest prefiks:
- dla rodzajów spraw to
typeTypeKinddla modelu 2.0 oraz typeKind dla modelu 3.0. Przykład nazwy pola dla modelu 3.0:mrc_typeKindValue. - dla rodzajów dokumentów to
c2docTypeTypeKinddla modelu 2.0 orazc2docTypeKinddla modelu 3.0.
- dla rodzajów spraw to
- TypeCase - pola reprezentujące dane dotyczące definicji typu (wersję typu) sprawy lub powiązanego ze sprawą dokumentu. W zależności od wykorzystywanego modelu nazewnictwa w systemie do podstawowych nazw pól encji dodawany jest prefiks:
- dla typów obiektów spraw to
type. Przykład nazw pól dla modelu 3.0:mrc_typeRootVersionContextID,mrc_typeTypeName. - dla typów obiektów dokumentów to
c2docType.
- dla typów obiektów spraw to
- Source - pola reprezentujące źródło pochodzenia sprawy albo powiązanego ze sprawą dokumentu. Do podstawowych nazw pól encji dodawany jest prefiks:
- dla obiektów spraw to
grSrc. - dla obiektów dokumentów to
c2docSrc. Przykład nazwy pola dla modelu 3.0:mrc_c2docSrcName.
- dla obiektów spraw to
- KtmNumber - pola reprezentujące dane powiązanego ze sprawą symbolu indeksu KTM (polski skrót Kod Towarowo-Materiałowy1, opisujący kod środka trwałego, zasobu).
- Prefiks nazwy pola to
grKtm. - Przykład nazwy pola dla modelu 3.0:
mrc_grKtmDescription.
- Prefiks nazwy pola to
- GroupCase - pola reprezentujące dane grupy spraw. Prefiks nazwy pola to
gr. - Participant - pola reprezentujące dane partycypantów sprawy (dane uczestników sprawy, klientów, których dotyczy sprawa).
- Prefiksy nazw pól:
grParticipant,grClient,grApplicant. Są to pola wielowartościowe. - Przykład nazwy pola dla modelu 3.0: "mrc_grClientIdentity".
- Prefiksy nazw pól:
- Case - pola reprezentujące pola predefiniowane dotyczące sprawy, nazywane również "polami nagłówka sprawy" - zobacz opis obiektu nagłówka sprawy CaseHeader. Do nazw pól nie jest dodawany żaden dodatkowy prefiks. Przykład nazwy pola status dla modelu 3.0:
mrc_status. - QuickTask - pola reprezentujące szybkie zadanie2 powiązane z sprawą. Prefiks nazwy pola to
qt. Przykład nazwy pola dla modelu 3.0:mrc_qtReplyText. - Comment - pola reprezentujące komentarze powiązane z sprawą. Prefiks nazwy pola to
comm. Przykład nazwy pola dla modelu 3.0:mrc_commContent. - CaseDocument - pola reprezentujące dokumenty powiązane z sprawą. Prefiks nazwy pola to
c2doc. Przykład nazwy pola dla modelu 3.0:mrc_c2docSubject. - InitStatus - pola reprezentujące inicjalny status dokumentu powiązanego z sprawą. Prefiks nazwy pola to
c2docInitStat. Przykład nazwy pola dla modelu 3.0:mrc_c2docInitStatName.
Pola dynamiczne - pola obiektów/spraw
Pola dynamiczne to pola, które są definiowane przez użytkowników i mogą być modyfikowane w trakcie działania systemu. Są to pola, które są specyficzne dla danej sprawy i mogą zawierać różne informacje w zależności od potrzeb użytkowników. Przykłady takich pól to: clientName, caseDescription, documentDate.
Wszystkie pola dynamiczne należą do kategorii Case.
Mamy trzy rodzaje pól dynamicznych dla których zdefiniowano inne zasady tworzenia ich nazewnictwa:
- Pola podstawowe - pola reprezentujące pola proste obiektu sprawy. Nazwy pól są takie jak je zdefiniowano w obiekcie.
- Pola skonfliktowane - pola reprezentujące pola proste obiektu sprawy, których nazewnictwo jest w konflikcie z nazewnictwem pól stałych/predefiniowanych. W zależności od wykorzystywanego modelu nazewnictwa pól, mamy następujące zasady tworzenia nazwy pola:
Dla modelu 2.0 nazewnictwa, z powodu braku prefiksu mrc_ w nazwach pól stałych, problem konfliktów nazw pól występował bardzo często. Dla modelu 3.0, dzięki prefiksowi mrc_, wystąpienie konfliktów w nazewnictwie pól zostało zminimalizowane do minimum. Nie używaj nazw pól, które występują w zbiorze pól stałych/predefiniowanych.
-
dla modelu 2.0 do nazwy pola dodawany jest prefiks
custom_. Przykład: pole obiektu o nazwiestatusprzyjmie nazwęcustom_status. -
dla modelu 3.0 do nazwy pola dodawany jest sufiks
_custom. Przykład: pole obiektu o nazwiemrc_statusprzyjmie nazwęmrc_status_custom. -
Klucze obce powiązane z encją
Case2SubCase- pola wskazujące na powiązania pomiędzy sprawami głównymi (nadrzędnymi) i zależnymi (podrzędnymi). Takie pola budowane są według następującej reguły:- dla modelu 2.0:
<nazwa_pola>_luceneDocId. Przykład:address_luceneDocId. - dla modelu 3.0:
<nazwa_pola>_mrc_Case_id. Przykład:address_mrc_Case_id.
- dla modelu 2.0:
Pola stałe nieklasyfikowane
Są to pola, które są wykorzystywane przez mechanizmy wewnętrzne bazy Mercury DB (HgDB) 3.0, lecz można je również wykorzystać do wyszukiwania spraw w zapytaniach do indeksu Lucene.
W zależności od wykorzystywanego modelu nazewnictwa nazwy pól budowane są według zasad:
- dla modelu 2.0 nazwa pola jest taka jak jest (as is).
- dla modelu 3.0 do nazwy pola dodawany jest prefiks
mrc_. Przykład:mrc_parentTypes.
Lista pól:
| Nazwa pola | Opis |
|---|---|
| parentFields | pole typu łańcucha znakowego (String), dodawane do dokumentu sprawy podrzędnej, wielowartościowe, zawiera nazwy pól spraw nadrzędnych, z którymi jest ona powiązana. Pole wspiera budowanie powiązań pomiędzy indeksowanymi dokumentami - powiązań pomiędzy sprawami głównymi (nadrzędnymi) i zależnymi (podrzędnymi). Przykład wartości pola to nazwa pola: address |
| parentTypes | pole typu łańcucha znakowego (String), dodawane do dokumentu sprawy podrzędnej, wielowartościowe, zawiera nazwy typów spraw nadrzędnych, z którymi jest ona powiązana. Pole wspiera budowanie powiązań pomiędzy indeksowanymi dokumentami - powiązań pomiędzy sprawami głównymi (nadrzędnymi) i zależnymi (podrzędnymi). Przykład wartości pola to nazwa typu sprawy: FsmService |
Typy pól indeksu Lucene
Jako, że typ pola ma wpływ na wykorzystywany przez indeks mechanizm wyszukiwania, alternatywnym pojęciem dla typu pola jest pojęcie typu wyszukiwania.
Podstawowe typy pól (typy wyszukiwania):
| Typ pola | Opis |
|---|---|
| TextField | Pole typu tekstowego, wyszukiwanie pełno tekstowe, bez rozróżniania wielkich i małych liter. |
| StringField | Pole typu prostego łańcucha znakowego, jedno wyrażenie, słowo. Najczęściej przeznaczone do definiowania wartości typu kod, akronim lub identyfikator. Wyszukiwanie z rozróżnianiem małych i wielkich liter. |
| LongField | Pole liczbowe, liczba całkowita, długa. Wyszukiwanie liczb, zakresy liczb. |
| DateField | Pole daty. Podczas indeksowania wartość pola z datą przekształcana jest do wartości liczby milisekund, do typu LongField. Pozwala na budowanie zakresu wyszukiwania. |
| IntField | Pole liczbowe, liczba całkowita, "krótka". |
| FloatField | Pole liczbowe, zmiennoprzecinkowe. |
| DoubleField | Pole liczbowe, zmiennoprzecinkowe. |
| CompositeIdField | Pole reprezentujące wartości kluczy złożonych encji. Wartość takiego pola przekształcana jest do typu StringField. Przykład: encja CaseDocument ma pole id klucza złożonego typu CaseDocumentPK. Wartość takiego pola indeksowana jest w postaci: "{\"caseId\":\"" + getCaseId() + "\", \"objectId\":\"" + objectId + "\", \"versionSeriesId\":\"" + versionSeriesId + "\"}" |
| SubQuery | Pola złożone, do których przypisana jest sprawa podrzędna. Aby wykorzystać to pole w wyszukiwaniu należy jego nazwę użyć jako prefiks odseparowany znakiem kropki, np. address.mrc_Case_id. |
Nazwy pól stałych/predefiniowanych
Stałe pola pochodzące z encji reprezentujących dane przechowywane w relacyjnej bazie danych.
TypeCode
Nazwy pól indeksu Lucene reprezentujące encję TypeCode. Pośród typów składowanych w systemie obiektów możemy wyróżnić dokumenty i sprawy. W celu ułatwienia wyszukiwania obiektów powiązanych ze składowanymi dokumentami (jako repozytorium dokumentów, w odróżnieniu do składowanych obiektów spraw) do nazw pól je reprezentujących dodano składową c2doc.
Lista nazw i znaczenie poszczególnych pól związanych z obiektami spraw
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | typeTypeCodeName [false] | mrc_typeCodeName [false] | Nazwa kodu typu - wartość reprezentująca kod typu sprawy. |
| value | StringField | typeTypeCodeValue [false] | mrc_typeCodeValue [true] | Wartość kodu typu - wartość reprezentująca kod typu sprawy. |
Lista nazw i znaczenie poszczególnych pól związanych z obiektami przechowywanych dokumentów
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | c2docTypeTypeCodeName [false] | mrc_c2docTypeCodeName [false] | Nazwa kodu typu - wartość reprezentująca kod typu składowanego dokumentu. |
| value | StringField | c2docTypeTypeCodeValue [false] | mrc_c2docTypeCodeValue [true] | Wartość kodu typu - wartość reprezentująca kod typu składowanego dokumentu. |
TypeKind
Nazwy pól indeksu Lucene reprezentujące encję TypeKind. Pośród typów składowanych w systemie obiektów możemy wyróżnić dokumenty i sprawy. W celu ułatwienia wyszukiwania obiektów powiązanych ze składowanymi dokumentami (jako repozytorium dokumentów, w odróżnieniu do składowanych obiektów spraw) do nazw p�ól je reprezentujących dodano składową c2doc.
Lista nazw i znaczenie poszczególnych pól związanych z obiektami spraw
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | typeTypeKindName [false] | mrc_typeKindName [false] | Nazwa rodzaju typu - wartość reprezentująca rodzaj typu sprawy. |
| value | StringField | typeTypeKindValue [false] | mrc_typeKindValue [true] | Wartość rodzaju typu - wartość reprezentująca rodzaj typu sprawy. |
Lista nazw i znaczenie poszczególnych pól związanych z obiektami przechowywanych dokumentów
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | c2docTypeTypeKindName [false] | mrc_c2docTypeKindName [false] | Nazwa rodzaju typu - wartość reprezentująca rodzaj typu składowanego dokumentu. |
| value | StringField | c2docTypeTypeKindValue [false] | mrc_c2docTypeKindValue [true] | Wartość rodzaju typu - wartość reprezentująca rodzaj typu składowanego. |
TypeCase
Nazwy pól indeksu Lucene reprezentujące encję TypeCase. Encja zawiera pole isDocument informujące o tym czy dany typ sprawy jest typem reprezentującym metadane dokumentu czy obiektu sprawy. W celu ułatwienia wyszukiwania obiektów powiązanych ze składowanymi dokumentami (jako repozytorium dokumentów, w odróżnieniu do składowanych obiektów spraw) do nazw pól je reprezentujących dodano składową c2doc.
Lista nazw i znaczenie poszczególnych pól związanych z obiektami spraw
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| accountNumber | StringField | typeAccountNumber [false] | mrc_typeAccountNumber [false] | Pole typu sprawy, numer/kod księgowy, pole predefiniowane, mające znaczenie podczas budowania systemów ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin. |
| description | TextField | typeDescription [false] | mrc_typeDescription [false] | Pole typu sprawy. Opis |
| - | StringField | typeSourceOfObject [false] | mrc_typeSourceOfObject [false] | Pole typu sprawy wskazujące na pochodzenie (źródło) definicji typu sprawy. Pole związane z typem sprawy, lecz znajduje się w encji TypeCase2SourceOfObject |
| id | StringField | typeLuceneDocId [true] | mrc_typeTypeCase_id [true] | Identyfikator typu sprawy. |
| typeName | StringField | typeTypeName [false] | mrc_typeTypeName [false] | Nazwa typu sprawy. |
Lista nazw i znaczenie poszczególnych pól związanych z obiektami przechowywanych dokumentów
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| accountNumber | StringField | c2docTypeAccountNumber [false] | mrc_c2docTypeAccountNumber [false] | Pole typu dokumentu, numer/kod księgowy, pole predefiniowane, mające znaczenie podczas budowania systemów ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin. |
| description | TextField | c2docTypeDescription [false] | mrc_c2docTypeDescription [false] | Pole typu dokumentu. Opis |
| - | StringField | c2docTypeSourceOfObject [false] | mrc_c2docTypeSourceOfObject [false] | Pole typu dokumentu wskazujące na pochodzenie (źródło) definicji typu dokumentu. Najczęściej wskazuje na nazwę zewnętrznego repozytorium dokumentów, pozwalającego na komunikację po protokole CMIS. Pole związane z typem sprawy, lecz znajduje sie w encji TypeCase2SourceOfObject |
| id | StringField | c2docTypeTypeCase_id [true] | mrc_c2docTypeTypeCase_id [true] | Pole typu dokumentu. |
| typeName | StringField | c2docTypeTypeName [false] | mrc_c2docTypeTypeName [false] | Pole typu dokumentu. nazwa typu. |
Source
Nazwy pól indeksu Lucene reprezentujące encję Source. Encja ta przechowuje informacje o źródłach spraw i dokumentów. Źródła te mogą być wykorzystywane do identyfikacji pochodzenia spraw i dokumentów, co jest przydatne w kontekście audytu i zarządzania danymi. Jako, że możemy wyróżnić typy dokumentów i typy spraw, w celu ułatwienia wyszukiwania dokumentów do nazw pól je reprezentujących dodano składową c2doc.
Lista i znaczenie poszczególnych pól związanych z obiektami spraw
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | grSrcName [false] | mrc_grSrcName [false] | Nazwa źródła grupy spraw |
| value | StringField | grSrcValue [false] | mrc_grSrcValue [true] | Identyfikator źródła grupy spraw |
Lista i znaczenie poszczególnych pól związanych z obiektami przechowywanych dokumentów
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | c2docSrcName [false] | mrc_c2docSrcName [false] | Nazwa źródła grupy składowanego dokumentu |
| value | StringField | c2docSrcValue [false] | mrc_c2docSrcValue [true] | Identyfikator źródła grupy składowanego dokumentu |
Oto przykładowe wartości reprezentujące źródła spraw i dokumentów:
value | name | description |
|---|---|---|
| SoapUI | SoapUI | Generated source from SoapUI |
| IMP_EXCEL | USER_DEV.localhost | Case imported from Excel file. |
| USER_DEV.localhost | USER_DEV.localhost | Generated source from USER_DEV.localhost |
| BPMProcessesSecretary | BPMProcessesSecretary | Generated source from BPMProcessesSecretary |
GroupCase
Nazwy pól indeksu Lucene reprezentujące encję *GroupCase. Rolą encji jest grupowanie spraw, które są ze sobą powiązane. Grupa spraw może być używana do zarządzania i organizowania spraw, które mają wspólne cechy lub są częścią większego procesu. W systemach ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin grupa spraw może definiować środek trwały, zasób. Dlatego też encja ta ma powiązanie z encją KtmNumber, która jest wykorzystywana do identyfikacji środka trwałego lub zasobu.
Wartości pól encji GroupCase są generowane automatycznie podczas tworzenia pojedynczej lub wielu spraw. Wartości te są unikalne dla każdej grupy spraw i nie powinny być modyfikowane ręcznie.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| id | StringField | grLuceneDocId [true] | mrc_grGroupCase_id [true] | Identyfikator grupy spraw. |
Case
Nazwy pól indeksu Lucene reprezentujące encję Case. Główna encja przechowująca dane sprawy. W zależności od wykorzystywanego modelu nazewnictwa, do podstawowych nazw pól encji dodawany jest prefiks mrc_ dla modelu 3.0. Większość predefiniowanych pól encji Case pełni rolę biznesową ukierunkowaną na wykorzystanie w systemach ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| id | StringField | luceneDocId [true] | mrc_Case_id [true] | Unikalny identyfikator sprawy/dokumentu |
| bpmProcessId | LongField | bpmProcessId [true] | mrc_bpmProcessId [true] | Identyfikator instancji procesu BPM, identyfikator z systemu zewnętrznego np. IBM BPM |
| bpmProcessId | StringField | bpmProcessIdNotNull [false] | mrc_bpmProcessIdNotNull [false] | Dodatkowe pole indeksu pozwalające na wyszukiwanie spraw, które nie maja powiązania z instancję procesu BPM. |
| createDate | LongField | createDate [true] | mrc_createDate [true] | Data utworzenia |
| createdBy | StringField | createdBy [true] | mrc_createdBy [true] | Nazwa użytkownika, który utworzył sprawę |
| createdByRoleName | StringField | createdByRoleName [true] | mrc_createdByRoleName [true] | Nazwa roli użytkownika, który utworzył sprawę |
| dueDate | LongField | dueDate [true] | mrc_dueDate [true] | Dane instancji procesu BPM: termin realizacji. |
| endDate | LongField | endDate [true] | mrc_endDate [true] | Dane instancji procesu BPM: data zakończenia instancji procesu, data zakończenia procesowania sprawy. |
| lastModifedBy | StringField | lastModifedBy [false] | mrc_lastModifedBy [false] | Nazwa użytkownika modyfikującego sprawę |
| lastModifiedByRoleName | StringField | lastModifiedByRoleName [false] | mrc_lastModifiedByRoleName [false] | Nazwa roli użytkownika modyfikującego sprawę |
| lastModifyDate | LongField | lastModifyDate [true] | mrc_lastModifyDate [true] | Data modyfikacji sprawy |
| piervousVersionId | StringField | piervousVersionId [true] | mrc_piervousVersionId [true] | Identyfikator wskazujący na poprzednią wersję sprawy |
| rootVersionId | StringField | rootVersionId [true] | mrc_rootVersionId [true] | Identyfikator wskazujący na główną, pierwszą wersję sprawy |
| inventoryCode | StringField | inventoryCode [true] | mrc_inventoryCode [true] | Kod inwentaryzacyjny - pole predefiniowane pod kątem wykorzystania systemu jako bazy środków trwałych. |
| inventoryCode | StringField | inventoryCodeReverse [false] | mrc_inventoryCodeReverse [false] | Dodatkowe pole indeksu, którego wartość przyjmuje wartość odwrotną do wartości pola inventoryCode . Przykład: gdy pole inventoryCode ma wartość "4/G/1231234" , wartość pola przyjmie "4321321/G/4". |
| priceValue | DoubleField | priceValue [true] | mrc_priceValue [true] | Wartość pieniężna sprawy - pole predefiniowane pod kątem wykorzystania systemu jako bazy środków trwałych |
| - | DoubleField | priceValueSys [false] | mrc_priceValueSys [false] | Wartość pieniężna sprawy w przeliczeniu na walutę systemową Mercury DB (HgDB) 3.0 - waluta systemowa jest konfigurowalna |
| priceValueCode | StringField | priceValueCode [false] | mrc_priceValueCode [false] | Kod waluty odpowiadający wartości pieniężnej sprawy np. EUR, PLN, $ - pole predefiniowane pod kątem wykorzystania systemu jako bazy środków trwałych. |
| priceExchangeDate | DoubleField | priceExchangeDate [false] | mrc_priceExchangeDate [false] | data wymiany waluty, przeliczenia wartość pieniężnej sprawy walutę systemową. |
| status | StringField | status [false] | mrc_status [false] | Status sprawy3, dozwolone wartości: A, O, N, Z |
| - | TextField | luceneDocumentMemo [false] | mrc_luceneDocumentMemo [false] | Pole tekstowe złożone z wartości większości pól sprawy. jego celem jest możliwość wyszukiwania spraw bez konieczności podawania nazwy pola reprezentującego wyszukiwaną wartość. |
Comment
Nazwy pól indeksu Lucene reprezentujące encję Comment, która przechowuje komentarze powiązane z obiektami spraw. Komentarze mogą być dodawane do spraw, dokumentów lub innych obiektów w systemie. O tym jak dodawać komentarze do spraw przeczytasz w artykule Komentarze do spraw.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| id | StringField | commLuceneDocId [true] | mrc_commComment_id [true] | Identyfikator komentarza |
| content | TextField | commContent [false] | mrc_commContent [false] | Treść komentarza |
| username | StringField | commUsername [false] | mrc_commUsername [false] | Nazwa użytkownika (login), który dodał komentarz |
QuickTask
Nazwy pól indeksu Lucene reprezentujące encję QuickTask2. Jak sama nazwa wskazuje, encja ta przechowuje dane o szybkich zadaniach powiązanych ze sprawami. Szybkie zadania mogą być dodawane do spraw, dokumentów lub innych obiektów w systemie. O tym jak dodawać szybkie zadania do spraw przeczytasz w artykule Szybkie zadania.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| description | TextField | qtDescription [false] | mrc_qtDescription [false] | Opis zadania. |
| from | StringField | qtFrom [false] | mrc_qtFrom [false] | Nadawca zadania, informacja o tym od kogo jest zadanie. |
| priority | StringField | qtPriority [false] | mrc_qtPriority [false] | Priorytet zadania |
| id | StringField | qtLuceneDocId [true] | mrc_qtQuickTask_id [true] | Unikalny identyfikator zadania. |
| replyDate | LongField | qtReplyDate [false] | mrc_qtReplyDate [false] | Data odpowiedzi |
| replyText | TextField | qtReplyText [false] | mrc_qtReplyText [false] | Komentarz odpowiedzi, opis podjętych kroków w celu realizacji zadania. |
| sendDate | LongField | qtSendDate [false] | mrc_qtSendDate [false] | Data przysłania zadania |
| to | StringField | qtTo [false] | mrc_qtTo [false] | Adresat zadania, do kogo zadanie jest kierowane. |
CaseDocument
Nazwy pól indeksu Lucene reprezentujące encję CaseDocument. Encja ta przechowuje dane o dokumentach powiązanych ze sprawami, które składowane są w zewnętrznym repozytorium dokumentów.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| id | CompositeIdField | c2docLuceneDocId [false] | mrc_c2docCaseDocument_id [false] | Reprezentacja identyfikatora dokumentu, który jest kluczem złożonym. Wartość pola przyjmuje postać: {\"caseId\":\"" + id.caseObj.id + "\", \"objectId\":\"" + id.objectId + "\", \"versionSeriesId\":\"" + id.versionSeriesId + "\"} |
| id.caseObj.id | LongField | c2docCaseId [false] | mrc_c2docCaseId [false] | Pole reprezentuje wartość identyfikatora sprawy, do której dany dokument został powiązany (składowa klucza obcego id ). |
| id.objectId | StringField | c2docObjectId [false] | mrc_c2docObjectId [false] | Identyfikator obiektu dokumentu w zewnętrznym repozytorium dokumentów. |
| id.versionSeriesId | StringField | c2docVersionSeriesId [false] | mrc_c2docVersionSeriesId [false] | Pole reprezentuje wartość wersji dokumentu (składowa klucza obcego id ). identyfikator wersji dokumentu w zewnętrznym repozytorium dokumentów. |
| author | TextField | c2docAuthor [false] | mrc_c2docAuthor [false] | Opis autora dokumentu. |
| contentStreamId | StringField | c2docContentStreamId [false] | mrc_c2docContentStreamId [false] | Identyfikator strumienia dokumentu w zewnętrznym repozytorium dokumentów. |
| groupingCode | StringField | c2docGroupingCode [false] | mrc_c2docGroupingCode [false] | Kod grupujący zbiór dokumentów |
| isInput | StringField | c2docIsInput [false] | mrc_c2docIsInput [false] | - |
| isRoot | StringField | c2docIsRoot [false] | mrc_c2docIsRoot [false] | - |
| receivedDate | LongField | c2docReceivedDate [false] | mrc_c2docReceivedDate [false] | Data przesłania |
| receiver | TextField | c2docReceiver [false] | mrc_c2docReceiver [false] | Przesyłający |
| receiverDW | TextField | c2docReceiverDW [false] | mrc_c2docReceiverDW [false] | Informację o przesyłającym "do wiadomości" |
| subject | TextField | c2docSubject [false] | mrc_c2docSubject [false] | Temat dokumentu |
| versionLabel | StringField | c2docVersionLabel [false] | mrc_c2docVersionLabel [false] | Etykieta wersji dokumentu. |
Participant
Nazwy pól indeksu Lucene reprezentujące encję Participant, która jest predefiniowaną encją w systemie Mercury DB (HgDB) 3.0. Ma znaczenie podczas budowania systemów ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin.
Partycypant to osoba ponosząca wspólnie z kimś koszty jakiegoś przedsięwzięcia lub mająca udział w zyskach płynących z jakiegoś przedsięwzięcia. W systemie Mercury DB (HgDB) 3.0 partycypantem sprawy może być klient, wnioskodawca, uczestnik sprawy, który jest powiązany z daną sprawą. Na podstawie pola kind, które określa jego rolę w sprawie wyróżnione są trzy rodzaje partycypantów: Client, Applicant i Participant. Aby uzyskać relację pomiędzy poszczególnymi rodzajem petenta a sprawami wykorzystano odpowiednie nazewnictwo pól indeksu Lucene.
Lista nazw i znaczenie poszczególnych pól dla partycypantów Client
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| contactPerson | TextField | grClientContactPerson [false] | mrc_grClientContactPerson [false] | - |
| StringField | grClientEmail [false] | mrc_grClientEmail [false] | - | |
| fullname | TextField | grClientFullname [false] | mrc_grClientFullname [false] | - |
| identity | StringField | grClientIdentity [false] | mrc_grClientIdentity [false] | - |
| - | TextField | grClientKindName [false] | mrc_grClientKindName [false] | - |
| id | StringField | grClientLuceneDocId [true] | mrc_grClientParticipant_id [true] | - |
| participantName | TextField | grClientParticipantName [false] | mrc_grClientParticipantName [false] | - |
| phone1 | StringField | grClientPhone1 [false] | mrc_grClientPhone1 [false] | - |
| phone2 | StringField | grClientPhone2 [false] | mrc_grClientPhone2 [false] | - |
Lista nazw i znaczenie poszczególnych pól dla partycypantów Applicant
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| contactPerson | TextField | grApplicantContactPerson [false] | mrc_grApplicantContactPerson [false] | - |
| StringField | grApplicantEmail [false] | mrc_grApplicantEmail [false] | - | |
| fullname | TextField | grApplicantFullname [false] | mrc_grApplicantFullname [false] | - |
| identity | StringField | grApplicantIdentity [false] | mrc_grApplicantIdentity [false] | - |
| - | TextField | grApplicantKindName [false] | mrc_grApplicantKindName [false] | - |
| id | StringField | grApplicantLuceneDocId [true] | mrc_grApplicantParticipant_id [true] | - |
| participantName | TextField | grApplicantParticipantName [false] | mrc_grApplicantParticipantName [false] | - |
| phone1 | StringField | grApplicantPhone1 [false] | mrc_grApplicantPhone1 [false] | - |
| phone2 | StringField | grApplicantPhone2 [false] | mrc_grApplicantPhone2 [false] | - |
Lista nazw i znaczenie poszczególnych pól dla partycypantów Participant
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| contactPerson | TextField | grParticipantContactPerson [false] | mrc_grParticipantContactPerson [false] | - |
| StringField | grParticipantEmail [false] | mrc_grParticipantEmail [false] | - | |
| fullname | TextField | grParticipantFullname [false] | mrc_grParticipantFullname [false] | - |
| identity | StringField | grParticipantIdentity [false] | mrc_grParticipantIdentity [false] | - |
| - | TextField | grParticipantKindName [false] | mrc_grParticipantKindName [false] | - |
| id | StringField | grParticipantLuceneDocId [true] | mrc_grParticipantParticipant_id [true] | - |
| participantName | TextField | grParticipantParticipantName [false] | mrc_grParticipantParticipantName [false] | - |
| phone1 | StringField | grParticipantPhone1 [false] | mrc_grParticipantPhone1 [false] | - |
| phone2 | StringField | grParticipantPhone2 [false] | mrc_grParticipantPhone2 [false] | - |
KtmNumber
Nazwy pól indeksu Lucene reprezentujące encję KtmNumber1. Encja jest wykorzystywana do przechowywania informacji o kodach KTM (Kod Towarowo-Materiałowy) powiązanych z grupą spraw (GroupCase) reprezentujących środek trwały. Kody KTM są używane do identyfikacji i klasyfikacji towarów i materiałów. KtmNumber to predefiniowana encja w systemie Mercury DB (HgDB) 3.0. Ma znaczenie podczas budowania systemów ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| description | TextField | grKtmDescription [false] | mrc_grKtmDescription [false] | Opis kodu, opis środka trwałego reprezentowanego przez dany kod. |
| groupCode | StringField | grKtmGroupCode [false] | mrc_grKtmGroupCode [false] | Kod grupy spraw. |
| ktmCode | StringField | grKtmKtmCode [false] | mrc_grKtmKtmCode [false] | Kod. |
| id | StringField | grKtmLuceneDocId [true] | mrc_grKtmKtmNumber_id [true] | Identyfikator kodu KTM. |
| priceValue | DoubleField | grKtmPriceValue [false] | mrc_grKtmPriceValue [false] | Wartość środka trwałego reprezentowanego przez dany kod. |
InitStatus
Nazwy pól indeksu Lucene reprezentujące encję InitStatus. Encja ta jest wykorzystywana do przechowywania informacji o inicjalnym statusie dokumentu powiązanego ze sprawą. Status ten może być używany do określenia stanu dokumentu na początku jego obiegu.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|---|
| name | TextField | c2docInitStatName [false] | mrc_c2docInitStatName [false] | - |
| value | StringField | c2docInitStatValue [false] | mrc_c2docInitStatValue [false] | - |
Case2SubCase
Nazwy pól indeksu Lucene reprezentujące encję Case2SubCase.
Lista nazw i znaczenie poszczególnych pól
| Typ wyszukiwania | Model 2.0 [sortowanie] | Model 3.0 [sortowanie] | Opis |
|---|---|---|---|
| StringField | parentFields [false] | mrc_parentFields [false] | Pole wielowartościowe, lista nazw pól, w których sprawa występuje jako sprawa podrzędna. |
| LongField | nazwa dynamiczna w postaci <nazwa_pola>LuceneDocId [false] | nazwa dynamiczna w postaci <nazwa_pola>_mrc_Case_id [false] | Identyfikator sprawy podrzędnej, gdzie <nazwa_pola> to nazwa pola, które ją reprezentuje w sprawie nadrzędnej. Pole wielowartościowe gdy z danym polem powiązana jest lista spraw. |
Predefiniowane typy złożone pól
Jest możliwość zdefiniowania pola typu "COMPLEX" ze wskazaniem implementacji klasy, która reprezentowała takie pole. Obecnie Mercury 3.0 (Hgdb) ma wbudowaną obsługę dwóch klas. Mają one znaczenie podczas budowania systemów ewidencji i planowania produkcji, gospodarki materiałowej, dokumentacji technicznej i innych dziedzin.
CaseClient
Nazwy pól indeksu Lucene reprezentujące klasę pro.ibpm.mercury.values.beans.CaseClient.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Nazwa [sortowanie] | Opis |
|---|---|---|---|
| clientType | StringField | caseclientClientType [false] | Typ klienta |
| companyName | TextField | caseclientCompanyName [false] | Nazwa firmy reprezentowanej przez klienta |
| contactPerson | TextField | caseclientContactPerson [false] | Osoba kontaktowa klienta |
| StringField | caseclientEmail [false] | Adres poczty elektronicznej | |
| name | TextField | caseclientName [false] | Nazwa |
| pesel | StringField | caseclientPesel [false] | Obowiązkowy identyfikator klienta np. jedna z reprezentujących klienta wartości: REGON4, PESEL5 albo NIP6 |
| phoneNumber1 | StringField | caseclientPhoneNumber1 [false] | Kontakt, nr telefonu 1 |
| phoneNumber2 | StringField | caseclientPhoneNumber2 [false] | Kontakt, nr telefonu 2 |
| regon | StringField | caseclientRegon [false] | Wartość opcjonalna, REGON3 |
| surname | TextField | caseclientSurname [false] | Nazwisko, nazwa rozszerzająca nazwę klienta |
CaseApplicant
Nazwy pól indeksu Lucene reprezentujące klasę pro.ibpm.mercury.values.beans.CaseApplicant.
Lista nazw i znaczenie poszczególnych pól
| Nazwa pola encji | Typ wyszukiwania | Nazwa [sortowanie] | Opis |
|---|---|---|---|
| agentNumber | StringField | caseapplicantAgentNumber [false] | Numer agenta, identyfikator agenta |
| applicantType | StringField | caseapplicantApplicantType [false] | Typ agenta |
| brokerName | TextField | caseapplicantBrokerName [false] | Nazwa brokera/agencji ubezpieczeniowej |
| workerName | TextField | caseapplicantWorkerName [false] | Nazwa zwykła pracownika/agenta |
Footnotes
-
Kod towarowo-materiałowy (KTM) - zbiór symboli i innych informacji identyfikujących towary występujące w obrocie lub materiały występujące w ewidencji, obowiązujący w kontaktach między dostawcami a odbiorcami, w korespondencji oraz w dokumentach obrotu towarowo-materiałowego. KTM jest również stosowany w ewidencji i planowaniu produkcji, gospodarce materiałowej, dokumentacji technicznej i w innych dziedzinach. Szczególnie ważny jest przy tworzeniu indeksów materiałowych, towarowych i wyrobów (pod redakcją I. Dudy 1994, s 71). Indeksami materiałowymi są to usystematyzowane wykazy materiałów zawierające nazwę i bliższe określenie materiału, jednostkę miary, inne cechy materiału istotne z punktu widzenia ewidencji oraz symbole cyfrowe. W przedsiębiorstwach mogą być stosowane branżowe indeksy materiałowe, zawierające materiały typowe dla danej branży, oraz indeksy zakładowe - dla materiałów stosowanych tylko w określonym przedsiębiorstwie. Indeksy materiałowe umożliwiają mechanizację ewidencji oraz czynności związane z planowaniem, sprawozdawczością i kontrolą zużycia materiałów (D. Dębski 2006, s 85). W obrocie międzynarodowym rodzajem takiego kodu jest GTIN. Źródło: Wikipedia. ↩ ↩2
-
Szybkie zadanie odzwierciedla działanie jednorazowe związane ze sprawą, ale niepowiązane z przepływem pracy. Osobom prowadzącym sprawę można umożliwić tworzenie szybkich zadań dla typu sprawy, aby mogły ułatwiać sobie organizowanie pracy i realizowanie nieoczekiwanych lub jednorazowych zadań. Na przykład można założyć, że osoba prowadząca sprawę uznaje, że konieczny jest telefon do klienta celem podtrzymania kontaktu. Osoba ta tworzy szybkie zadanie dokumentujące tę konieczność. Osoba prowadząca sprawę może następnie przypisać szybkie zadanie innej osobie prowadzącej sprawę i wyznaczyć termin realizacji. Szybkie zadania są wyświetlane w widgecie Lista zadań z listą kontrolną. Osoba prowadząca sprawę może utworzyć szybkie zadanie, po prostu wpisując jego nazwę. Po utworzeniu zadania osoba prowadząca sprawę może dodać opis, przypisać zadanie i wyznaczyć termin realizacji. Szybkie zadanie oznacza się jako zamknięte, klikając je jednokrotnie w widgecie Lista zadań z listą kontrolną. Źródło: IBM Documentation. ↩ ↩2
-
Status sprawy jest polem predefiniowanym, które może być wykorzystywane do określenia stanu sprawy. Dozwolone wartości to:
A(aktywna),O(otwarta),N(nieaktywna),Z(zamknięta). Wartość pola jest wykorzystywana do filtrowania spraw w interfejsie użytkownika i podczas wyszukiwania spraw w indeksie Lucene. ↩ ↩2 -
REGON (Rejestr Gospodarki Narodowej), Krajowy Rejestr Urzędowy Podmiotów Gospodarki Narodowej – rejestr prowadzony przez Prezesa Głównego Urzędu Statystycznego. Pod pojęciem REGON-u rozumiany jest także numer identyfikacyjny REGON, czyli dziewięciocyfrowy identyfikator nadany podmiotowi w tym rejestrze. Źródło: Wikipedia. ↩
-
PESEL – Powszechny Elektroniczny System Ewidencji Ludności – centralny zbiór danych prowadzony w Polsce przez ministra właściwego do spraw informatyzacji (do końca 2015 r. przez ministra właściwego do spraw wewnętrznych) na mocy ustawy o ewidencji ludności. Rejestr służy do gromadzenia podstawowych informacji identyfikujących tożsamość i status administracyjno-prawny obywateli polskich oraz cudzoziemców zamieszkujących na terenie Rzeczypospolitej Polskiej. Potocznie mianem PESEL określa się również numer ewidencyjny osoby fizycznej wykorzystywany w tym rejestrze. Źródło: Wikipedia. ↩
-
NIP - Numer identyfikacji podatkowej – dziesięciocyfrowy kod, służący do identyfikacji podatników w Polsce. Wprowadziła go ustawa z października 1995, a zaczął obowiązywać od 1996. Nadawany jest przez naczelnika urzędu skarbowego. Od 1 września 2011 roku osoby fizyczne nieprowadzące działalności gospodarczej używają numeru PESEL jako identyfikatora podatkowego. Źródło: Wikipedia. ↩