PagedResult jako lista pobieranych danych
Opis i przykład realizacji implementacji danych wyjściowych PagedResult, nazywany również wynikiem stronicowanym. Opisany format przesyłanych danych ma zastosowanie wszędzie tam, gdy w odpowiedzi na żądanie zwracane są listy o bardzo dużym wolumenie, których klient nie jest w stanie przetworzyć w jednej operacji, gdzie koniecznością jest podział tych list na strony. PagedResult jest pewnego rodzaju standardem odpowiedzi wykorzystywanym w komunikacji z systemem HgDB. W niniejszym rozdziale opisana została struktura typu w postaci JSON (dla usług REST) oraz XML (dla usług SOAP). Obiekt ma też swoją reprezentację (implementację) w Java i tam jest wykorzystywany w komunikacji RMI.
PagedResult
| Warstwy, w których użyty | Business |
| Rodzaj | Obiekt biznesowy |
| Interfejs Java | pro.ibpm.mercury.logic.paging.IPagedResult<E,P extends IPage>, IMrcObject, IMrcPropertyAttrs |
| Implementacja Java | pro.ibpm.mercury.dto.paging.PagedResult<E> |
| Implementacja DTO | pro.ibpm.mercury.dto.paging.PagingInfoTransportable |
| Definicja XML | hgdb-mrc-object-3.0.xsd |
Stronicowany wynik. Obiekt reprezentujący wynik odpowiedzi na żądanie wysłane do usług prezentujących listy oraz realizujących mechanizmy wyszukiwania spraw w systemie HgDB. Definicja obiektu jest parametryzowana (zobacz implementacja Java), gdzie parametr E to definicja elementu listy, którą reprezentuje. Interfejs obiektu zawiera jeszcze parametr P, który reprezentuje definicję obiektu strony, ale we wszystkich implementacjach zastosowanych w HgDB, jest on reprezentowany przez jedną definicję opisaną w tym artykule.
Obiekt PagedResult posiada wiele implementacji, które wykorzystywane są w warstwach logicznej i biznesowej. Jako, że jest to reprezentacja listy danych, możemy wyróżnić dwie głowne implementacje:
- implementacja
MrcPagedResultprzechowująca na liście obiekty typuMrcObject(zobacz Case jako uniwersalny obiekt MRC), - implementacja przechowująca na liście dowolne obiekty reprezentujące sprawy (zobacz Case jako dowolny obiekt)
Stałe parametry
PagedResult występuje w implmentacji jako uniwersalny obiekt MrcObject (zobacz Case jako uniwersalny obiekt MRC) o nazwie MrcPagedResult. W jego przypadku nie ma możliwości dodawania własnych parametrów, ponieważ nie jest to obiekt predefiniowany przez system, w odróżnieniu od definicji obiektów spraw. Wartości parametrów są stałe i zdefiniowane w implementacji.
<propertyNames>
<propertyName>resultSize</propertyName>
<propertyName>result</propertyName>
<propertyName>message</propertyName>
<propertyName>executionTime</propertyName>
<propertyName>currentPageInfo</propertyName>
<propertyName>firstPageInfo</propertyName>
<propertyName>previousPageInfo</propertyName>
<propertyName>nextPageInfo</propertyName>
<propertyName>lastPageInfo</propertyName>
<propertyName>allPages</propertyName>
<propertyName>pagingParams</propertyName>
</propertyNames>
resultSize
| Nazwa parametru | resultSize |
| Typ | Long |
Parametr określający liczbę wszystkich znalezionych elementów. W przypadku, gdy nie znaleziono żadnych elementów, wartość tego parametru wynosi 0.
Jeżeli kontekście żądania (zobacz definicję obiektu Context) ustawione jest pole maxResults to musimy mieć świadomość, że jeżeli w systemie istnieje więcej elementów, to resultSize przyjmie wartość zdefiniowaną w tym polu.
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do przekazania informacji o pełnym rozmiarze wyniku:

result
| Nazwa parametru | result |
| Typ | List<ANY>, MrcList |
Lista elementów występująca na danej stronie wyniku. Definicja elementu jest zależna od wywołanej usługi (pamiętaj, że obiekt jest parametryzowany). O tym jak zdefiniowany jest element listy powinieneś się dowiedzieć w opisie usługi/metody, którą wykorzystałeś by ją pobrać.
Długość listy zależy od deklarowanego rozmiaru strony zdefiniowanego w żądaniu wysłanym do usługi.
Poniżej przykład definicji listy w JSON jako implementacja listy obiektów ANY spraw bez nagłówków1:
[
{
"status": "Aktywny",
"name": "aatest",
"priv": "RO",
"users": [
"slawa1233",
"slawas2",
"slawas3",
"slawas4",
"ttest2345"
]
},
{
"status": "Aktywny",
"name": "wtest",
"priv": "RW",
"users": [
"slawa1233",
"slawas2",
"slawas3",
"slawas4",
"ttest2345"
]
}
]
W przypadku implementacji listy obiektów MrcObject (zobacz Case jako uniwersalny obiekt MRC) lista będzie zawierała obiekty MrcObject, które są reprezentacją spraw w systemie HgDB.
message
| Nazwa parametru | message |
| Typ | String |
Komunikat związany z wynikiem. Może przyjmować następujące wartości:
FRAGMENT- oznacza to, że lista elementów zawarta w polu result jest tylko fragmentem całego wyniku. Wartość charakterystyczna dla strony wyniku, która nie jest ostatnią stroną (istnieją kolejne strony danego wyniku).ALL- oznacza, że zostały pobrane już wszystkie elementy wyniku. Wartość charakterystyczna dla strony wyniku, która jest ostatnią stroną (nie istnieją kolejne strony danego wyniku albo jest to ostatnia strona pobieranego wyniku).NO_DATA_FOUND- oznacza, że wynik jest pusty, nie znaleziono danych.
executionTime
| Nazwa parametru | executionTime |
| Typ | Long |
Pole informacyjne, czas wykonania żądania przez usługę, określony w milisekundach.
currentPageInfo
| Nazwa parametru | currentPageInfo |
| Typ | Page, MrcPage |
Dane dotyczące definicji obecnej strony wyniku. Zawiera numer strony oraz jej rozmiar.
{
"size": 20,
"number": 2
}
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do przekazania informacji o tym, na której stronie wyniku się znajdujemy:

firstPageInfo
| Nazwa parametru | firstPageInfo |
| Typ | Page, MrcPage |
Dane na temat pierwszej strony wyniku. Zawiera numer strony oraz jej rozmiar.
{
"size": 20,
"number": 1
}
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do stworzenia linku przejścia na pierwszą stronę wyniku.
previousPageInfo
| Nazwa parametru | previousPageInfo |
| Typ | Page, MrcPage |
Dane na temat poprzedniej strony wyniku. Zawiera numer strony oraz jej rozmiar.
{
"size": 20,
"number": 1
}
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do stworzenia linku przejścia na stronę poprzednią:

nextPageInfo
| Nazwa parametru | nextPageInfo |
| Typ | Page, MrcPage |
Dane na temat następnej strony wyniku. Zawiera numer strony oraz jej rozmiar.
{
"size": 20,
"number": 3
}
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do stworzenia linku przejścia na stronę następną:

lastPageInfo
| Nazwa parametru | lastPageInfo |
| Typ | Page, MrcPage |
Dane na temat ostatniej strony wyniku. Zawiera numer strony oraz jej rozmiar.
{
"size": 20,
"number": 246
}
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę wartość do stworzenia linku przejścia na ostatnią stronę wyniku.

allPages
| Nazwa parametru | allPages |
| Typ | List<Page>, List<MrcPage> |
Lista definicji maksymalnie 10 stron występujących w pobliżu obecnej strony.
[
{
"size": 20,
"number": 1
},
{
"size": 20,
"number": 2
},
{
"size": 20,
"number": 3
},
//...
]
Przypadek użycia: Podczas implementacji panelu sterującego w tabeli prezentacji wyniku na stronach WWW, możemy wykorzystać tę listę do stworzenia linków kierujących do najbliższych stron.

pagingParams
| Nazwa parametru | pagingParams |
| Typ | PagingParams, MrcPagingParams |
Definicja stronicowania, parametry budowania stron przesłanego wyniku. Dane pomocnicze, prezentujące zasady tworzenia stronicowanego wyniku.
{
"offset": 0,
"cursorOfPage": 20,
"maxPageSize": 20,
"maxCount": 10000,
"pageSize": 20,
"page": {
"size": 20,
"number": 1
},
"valid": "true",
"isReadOnly": "false"
}
Pobieranie pełnego wyniku
W rozwiązaniach backend'owych bardzo często spotkać się możemy, z problemem pobrania całego wyniku, np. podczas wykonywania operacji eksportu danych, transferu danych pomiędzy systemami. Poniżej przedstawiam przykładowy algorytm pobierania wszystkich wyników. Oczywiście samą implementację pobierania całego wyniku możemy rozproszyć na wiele wątków, wszystko zależy od tego jakie są wymagania biznesowe realizowanego projektu oraz umiejętności programistów go realizujących.
Algorytm pobierania danych
Przedstawiony algorytm pokazuje jak przydatnym jest posługiwanie się obiektem PagedResult. Szczególnie podczas przetwarzania (przesyłania) dużego wolumenu danych uzyskanych od usług HgDB. Operacja może być przerywana i kontynuowana w dowolnym punkcie pobierania wyniku.
Opis poszczególnych kroków algorytmu:
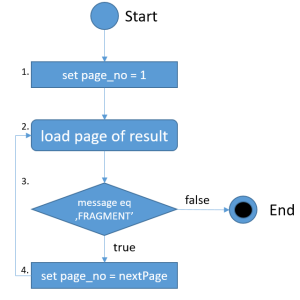 |
|
Pobieranie wielowątkowe
Na podstawie danych składowanych w polach resultSize oraz pagingParams.pageSize możemy zdefiniować liczbę równoległych wątków i podzielić pracę by skrócić czas pobierania danych np. (bardzo prosty przykład) dla wartości:
resultSize= 120pagingParams.pageSize= 20
Uruchomimy 3 wątki, które równolegle pobierać będą dane:
- wątek pierwszy pobiera strony 1 i 2
- wątek drugi pobiera strony 3 i 4
- wątek trzeci pobiera strony 5 i 6
To pozwoli, teoretycznie, trzykrotnie skrócić czas pobierania całego wyniku.
Estymacja czasu pobierania
Dodatkowo możemy wykorzystać wartość pola executionTime oraz lastPageInfo.pageSize do estymacji pobrania całego wyniku. W przykładzie, w którym:
executionTime= 643[ms]lastPageInfo.number= 246
Możemy estymować czas zakończenia operacji:
- dla pobierania w jednym wątku estymowany czas zakończenia to
executionTime * lastPafeInfo.number=>643[ms] * 246 = 158178[ms]=~ 158[s]=~ 2,5[min]. - dla pobierania w pięciu watkach estymowany czas zakończenia operacji może skrócić się do
30[s].
Oczywiście możemy tak napisać mechanizm pobierania, że estymowany czas możemy modyfikować wraz z przychodzącymi kolejnymi danymi (stronami danych), które zaktualizują nam informację o czasie wykonania operacji na pojedynczej stronie, oraz liczbą pozostałych do pobrania stron. Należy podkreślić, że czas pobrania pierwszej strony wyniku zawiera również czas wykonania odpowiedniego zapytania, a dane pozostałych stron przechowywane mogą być w pamięci podręcznej systemu - zależy to też od konfiguracji HgDB, a mianowicie jak długi zdefiniowany jest czas ekspiracji wyniku w pamięci podręcznej - domyślna wartość to 5 minut.
ExcelData
| Warstwy, w których użyty | Business |
| Rodzaj | Obiekt biznesowy, zewnętrzny |
| Interfejs Java | org.iron.poi.excel.core.api.IExcelData |
| Implementacja Java | org.iron.poi.excel.core.beans.ExcelData |
| Implementacja DTO | org.iron.poi.excel.core.beans.ExcelData |
ExcelData to szczególna implementacja stronicowanego wyniku wyszukiwania (PagedResult). Typ ten stanowi swego rodzaju standard komunikacji pomiędzy poszczególnymi komponentami systemu HgDB i jest wykorzystywany jako uniwersalny nośnik danych w postaci relacji (tablic).
Standard ten został utworzony w ramach projektu Iron - POI Excel Serwer do prezentacji danych składowanych w plikach Excel - stąd też jego nazwa. Implementacja Java obiektu znajduje się w bibliotece implementacji produktu Iron.
W tej implementacji elementem listy pola result jest mapa wartości, której kluczem jest nazwa kolumny zgodna z nazewnictwem wykorzystywanym w arkuszu kalkulacyjnym Excel. Dodatkowo, w celu identyfikacji wiersza wyniku dodano pozycję o nazwie rowIndx, która reprezentuje klucz unikalny przesyłanych danych i zawiera numer wiersza zwracanego wyniku.
{
"A": "2019-01-02 13",
"B": "0",
"C": "4",
"rowIndx": "60"
}
Jako, że element listy nie zawiera wszystkich danych pozwalających na pełen opis relacji, do implementacji ExcelData dodano następujące pola.
header
| Nazwa parametru | header |
| Typ | Map |
Nagłówek, dodatkowe dane reprezentujące nazwy poszczególnych kolumn. Jest to mapa, której kluczem jest nazwa kolumny Excel, a wartością jest dostosowana nazwa tej kolumny.
{
"A": "Date",
"B": "mrc_createDate",
"C": "mrc_endDate"
}
columnTypes
| Nazwa parametru | columnTypes |
| Typ | Map |
Definicje typów kolumn. Jest to mapa, której kluczem jest nazwa kolumny Excel, a wartością jest typ tej kolumny. Poniżej lista możliwych nazw typów kolumn:
STRING- reprezentuje typ obiektu Javajava.lang.StringINTEGER- reprezentuje typ obiektu Javajava.lang.IntegerINT- reprezentuje typ prymitywny JavaintLONG- reprezentuje typ obiektu Javajava.lang.LongSHORT- reprezentuje typ obiektu Javajava.lang.ShortFLOAT- reprezentuje typ obiektu Javajava.lang.FloatDOUBLE- reprezentuje typ obiektu Javajava.lang.DoubleBIGDECIMAL- reprezentuje typ obiektu Javajava.lang.BigDecimalBYTE- reprezentuje typ obiektu Javajava.lang.ByteBOOLEAN- reprezentuje typ obiektu Javajava.lang.BooleanDATE- reprezentuje typ obiektu Javajava.lang.DateCALENDAR- reprezentuje typ obiektu Javajava.lang.Calendar
{
"A": "Date",
"B": "mrc_createDate",
"C": "mrc_endDate"
}
Przykład prezentacji obiektu ExcelData
Przykład prezentacji obiektu ExcelData w postaci JSON
{
"result": [
{
"A": "2019-02-01 10",
"B": "1",
"C": "0",
"rowIndx": "1"
},
{
"A": "2019-02-01 09",
"B": "6",
"C": "0",
"rowIndx": "2"
},
{
"A": "2019-01-25 13",
"B": "22796",
"C": "0",
"rowIndx": "3"
},
{
"A": "2019-01-24 21",
"B": "649",
"C": "0",
"rowIndx": "4"
},
{
"A": "2019-01-23 08",
"B": "7",
"C": "0",
"rowIndx": "5"
},
{
"A": "2019-01-21 18",
"B": "1",
"C": "0",
"rowIndx": "6"
},
{
"A": "2019-01-21 15",
"B": "11",
"C": "0",
"rowIndx": "7"
},
{
"A": "2019-01-12 04",
"B": "1",
"C": "0",
"rowIndx": "8"
},
{
"A": "2019-01-12 03",
"B": "23809",
"C": "0",
"rowIndx": "9"
},
{
"A": "2019-01-10 15",
"B": "0",
"C": "4",
"rowIndx": "10"
},
{
"A": "2019-01-10 14",
"B": "0",
"C": "2",
"rowIndx": "11"
},
{
"A": "2019-01-10 13",
"B": "0",
"C": "2",
"rowIndx": "12"
},
{
"A": "2019-01-10 12",
"B": "0",
"C": "4",
"rowIndx": "13"
},
{
"A": "2019-01-10 11",
"B": "0",
"C": "2",
"rowIndx": "14"
},
{
"A": "2019-01-10 10",
"B": "0",
"C": "2",
"rowIndx": "15"
},
{
"A": "2019-01-10 07",
"B": "0",
"C": "2",
"rowIndx": "16"
},
{
"A": "2019-01-10 05",
"B": "0",
"C": "6",
"rowIndx": "17"
},
{
"A": "2019-01-09 20",
"B": "0",
"C": "2",
"rowIndx": "18"
},
{
"A": "2019-01-09 16",
"B": "0",
"C": "2",
"rowIndx": "19"
},
{
"A": "2019-01-09 15",
"B": "0",
"C": "4",
"rowIndx": "20"
}
],
"message": "FRAGMENT",
"resultSize": 134,
"currentPageInfo": {
"size": 20,
"number": 1
},
"firstPageInfo": {
"size": 20,
"number": 1
},
"previousPageInfo": {
"size": 20,
"number": 1
},
"nextPageInfo": {
"size": 20,
"number": 2
},
"lastPageInfo": {
"size": 40,
"number": 7
},
"header": {
"A": "Date",
"B": "mrc_createDate",
"C": "mrc_endDate"
},
"columnTypes": {
"A": "STRING",
"B": "LONG",
"C": "LONG"
}
}
QueryStats
| Warstwy, w których użyty | Business |
| Rodzaj | Obiekt biznesowy |
| Interfejs Java | - |
| Implementacja Java | org.mercury.lucene.query.QueryStats#QueryStatsCollector |
| Implementacja DTO | org.mercury.lucene.query.QueryStats#QueryStatsCollector |
QueryStats - szczegółowe statystyki wykonania zapytania. Obiekt jest załączany (nie zawsze - zobacz szczegóły opisu odpowiedzi metody danej usługi) do odpowiedzi usługi realizującej akcję wyszukiwania i agregacji danych w indeksie Lucene. Analiza jego wartości może wspomóc optymalizację zapytań wykonywanych przez aplikację. Obiekt ma następujące pola:
| Pole | Opis | Typ | Przykład |
|---|---|---|---|
| allExecTime | Czas wykonania zapytana wyrażony w milisekundach. | Long | 1339 |
| mainPrepareTime | Czas poświęcony na przygotowanie zapytania (parsowanie, przygotowanie planu wykonania itp.) wyrażony w milisekundach. | Long | 11 |
| collValidationTime | Czas poświęcony na walidacja danych kolektora (suma wszystkich walidacji) - czas wyrażony w milisekundach. | Long | 1 |
| mainCollExecTime | Czas wykonania kolektora głównego (suma wszystkich wywołań)- czas wyrażony w milisekundach. | Long | 0 |
| mainCollExecCount | Liczba wywołań kolektora głównego (liczba przetworzonych dokumentów, weryfikacja kryteriów wyszukiwania). | Long | 47281 |
| subCollExecTime | Czas wykonania kolektora zależnego (suma wszystkich wywołań) - czas wyrażony w milisekundach. | Long | 4 |
| subCollExecCount | Liczba wywołań kolektora zależnego (liczba przetworzonych dokumentów, weryfikacja kryteriów wyszukiwania). | Long | 8 |
| subExecLeve1Time | Czas wykonania zapytań na poziomie 1 (dla zapytań z podzapytaniami, kryteria dla pól spraw złożonych) - czas wyrażony w milisekundach. | Long | 1337 |
| subExecLeve2Time | Czas wykonania zapytań na poziomie 2 (dla zapytań z podzapytaniami, kryteria dla pól spraw złożonych oraz agregacji danych) - czas wyrażony w milisekundach. | Long | 0 |
| subExecLeve3Time | Czas wykonania zapytań na poziomie 3 (dla zapytań z podzapytaniami, kryteria dla pól spraw złożonych oraz agregacji danych) - czas wyrażony w milisekundach. | Long | 0 |
| subExecLeve4Time | Czas wykonania zapytań na poziomie 4 (dla zapytań z podzapytaniami, kryteria dla pól spraw złożonych oraz agregacji danych) - czas wyrażony w milisekundach. | Long | 0 |
| initResultSetTime | Czas poświęcony na przygotowanie wyniku wyrażony w milisekundach. | Long | 6 |
| resultSetSize | Całkowity wynik rozmiaru. | Long | 3 |
{
"allExecTime": 1339,
"mainPrepareTime": 11,
"collValidationTime": 1,
"mainCollExecTime": 0,
"mainCollExecCount": 47281,
"subCollExecTime": 4,
"subCollExecCount": 8,
"subExecLeve1Time": 1337,
"subExecLeve2Time": 0,
"subExecLeve3Time": 0,
"subExecLeve4Time": 0,
"initResultSetTime": 6,
"resultSetSize": 3
}
Footnotes
-
W odpowiedzi na żądanie pobrania listy spraw wynik może nie zawierać nagłówków spraw. O tym czy nagłówek sprawy ma występować w wyniku decyduje parametr
ignoreCaseHeaderInResponse(ignoruj nagłówek spraw w odpowiedzi) przekazany w obiekcie kontekstu w żądaniu do usługi. Parametr ten przyjmuje wartości logicznetruealbofalse. Domyślna wartość tego parametru tofalse, zatem, gdy nie jest on ustawiony, nagłówek sprawy jest zwracany. ↩