Index Lucene
The basis for searching in the Mercury DB system is the [Lucene] Index (https://lucene.apache.org). This article will present the principles of creating field names, which are the basis for implementing search queries. It will also present the division of fields according to their type, category (division according to field origin) and search method (division according to field type). The Lucene Index is very flexible and allows for the creation of specialized queries that can be adapted to various user needs. It is worth noting that the Lucene Index is used not only in the Mercury DB system, but also in many other database systems and Internet search engines.
Due to the development of the system and new requirements, the Lucene index field names have been developed in two models: Model 2.0 and Model 3.0. The choice of the field naming model is defined in the system configuration parameters. The naming model used is defined by the mercury.lucene.model.version parameter of the system configuration stored in the mercury.properties file. The parameter takes one of two values: 2 or 3.
Index document structure
The Lucene index document in the Mercury DB system is based on data stored in a relational database.
The Lucene index model is defined during the Mercury DB system installation process. It is worth noting that this model is closely related to the system architecture and its functionalities. In the event of a change in the index model, it is necessary to rebuild the Lucene index and make appropriate changes in the applications performing data search tasks
The entity diagram below presents the individual elements of the document, which are stored in the relational database. Each entity is represented by corresponding fields in the Lucene index document (see Fixed/Predefined Field Names).
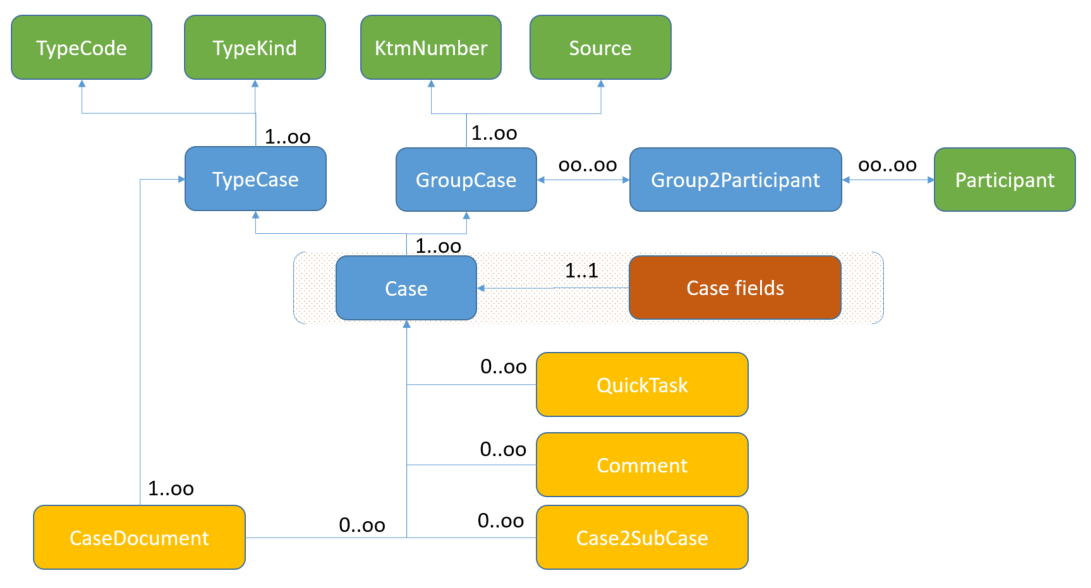
Storing a document in an index
The architecture of the data stored in a relational database means that one Lucene index document corresponds to one entry (row) in the table representing the Case entity. The object-oriented nature of the stored data introduces the need to build relationships between indexed documents. To explain this in more detail, let's analyze the following case of an example object of a complex case definition named EliAddress:

We have a parent case (EliClient, parent) and a child case (EliAddress, child). Their data is stored as separate rows in the table. The relationship that exists between them (the clientAddress field in the parent case) is stored in the relational database as a row of the Case2SubCase entity. To reflect this relationship in indexed documents, the HgDB indexing engine adds appropriate fields to both the parent and child case documents.
A field will be added to the parent case document (EliClient, parent) with a name created according to the rule: <field_name>_<field_name_with_case_id>, i.e. in our case, using the 3.0 model naming convention, clientAddress_mrc_Case_id with a value corresponding to the child case identifier. A field is created that is the equivalent of a foreign key in a relational database. This will allow the Mercury DB (HgDB) 3.0 engine to execute the appropriate binding query, search for a child case with the appropriate identifier.
Two multi-valued fields will be added to the child case document (EliAddress, child):
parentFields- a field with the name of the binding field, to which in our case the valueclientAddresswill be addedparentTypes- a field with the name of the parent case type, to which in our case the valueEliClientwill be added
This will allow for optimization of queries that allow finding the parent case.
Rules for building field names
In the Lucene index document, we can distinguish two main types of fields: fixed/predefined fields and dynamic fields. Different rules for creating Lucene index field names have been created for each type.
Fixed/predefined fields
Fixed/predefined fields are fields that are defined in the Lucene index model and cannot be modified by users. These are fields that are necessary for the system to function properly and are used to store basic information about documents. Examples of such fields are: mrc_Case_id, mrc_Case_type, mrc_Case_status.
A division of fields has been introduced, due to their origin, in the form of field categories. Categories represent entities, and their names are the names of entities in which the fields appear.
To distinguish this type of field from case object fields (dynamic fields), in Model 3.0 the naming of all constant fields has been provided with an additional prefix mrc_.
Below are the rules for naming fields based on their category assignment:
- TypeCode - fields representing data regarding the definition of the case type code or the document type associated with the case. Depending on the naming model used in the system, a prefix is added to the basic names of entity fields:
- for case object types, this is
typeTypeCodefor the 2.0 model and typeCode for the 3.0 model. Example field name for the 3.0 model:mrc_typeCodeValue. - for document object types, this is
c2docTypeTypeCodefor the 2.0 model andc2docTypeCodefor the 3.0 model.
- for case object types, this is
- TypeKind - fields representing data regarding the type of case type or the document associated with the case. Depending on the naming model used in the system, a prefix is added to the basic names of entity fields:
- for case types it is
typeTypeKindfor the 2.0 model and typeKind for the 3.0 model. Example field name for the 3.0 model:mrc_typeKindValue. - for document types it is
c2docTypeTypeKindfor the 2.0 model andc2docTypeKindfor the 3.0 model.
- for case types it is
- TypeCase - fields representing data regarding the type definition (type version) of the case or the document associated with the case. Depending on the naming model used in the system, a prefix is added to the basic names of entity fields:
- for case object types it is
type. Example field names for the 3.0 model:mrc_typeRootVersionContextID,mrc_typeTypeName. - for document object types it is
c2docType.
- for case object types it is
- Source - fields representing the source of the case or document related to the case. A prefix is added to the basic names of entity fields:
- for case objects it is
grSrc. - for document objects it is
c2docSrc. Example of a field name for the 3.0 model:mrc_c2docSrcName.
- for case objects it is
- KtmNumber - fields representing data of the KTM index symbol related to the case (Polish abbreviation Kod Towarowo-Materiałowy1, describing the code of the fixed asset, resource).
- The field name prefix is
grKtm. - Example of a field name for the 3.0 model:
mrc_grKtmDescription.
- The field name prefix is
- GroupCase - fields representing data of the group of cases. The field name prefix is
gr. - Participant - fields representing case participant data (case participant data, clients affected by the case).
- Field name prefixes:
grParticipant,grClient,grApplicant. These are multi-valued fields. - Example of a field name for the 3.0 model: "mrc_grClientIdentity".
- Field name prefixes:
- Case - fields representing predefined fields related to the case, also called "case header fields" - see the description of the [CaseHeader case header] object (/docs/API/CaseHeader). No additional prefix is added to the field names. Example of a status field name for the 3.0 model:
mrc_status. - QuickTask - fields representing a quick task2 associated with the case. The field name prefix is
qt. Example of a field name for the 3.0 model:mrc_qtReplyText. - Comment - fields representing comments associated with the case. The field name prefix is
comm. Example of a field name for the 3.0 model:mrc_commContent. - CaseDocument - fields representing documents associated with the case. The field name prefix is
c2doc. Example of a field name for the 3.0 model:mrc_c2docSubject. - InitStatus - fields representing the initial status of a document associated with the case. The field name prefix is
c2docInitStat. Example of a field name for the 3.0 model:mrc_c2docInitStatName.
Dynamic fields - object/case fields
Dynamic fields are fields that are defined by users and can be modified during system operation. These are fields that are specific to a given case and can contain different information depending on the needs of users. Examples of such fields are: clientName, caseDescription, documentDate.
All dynamic fields belong to the Case category.
We have three types of dynamic fields for which different rules for creating their names have been defined:
- Basic fields - fields representing simple fields of the case object. Field names are as they are defined in the object.
- Conflicted fields - fields representing simple fields of the case object, the names of which are in conflict with the names of fixed/predefined fields. Depending on the field naming model used, we have the following rules for creating a field name:
For the 2.0 naming model, due to the lack of the mrc_ prefix in the names of fixed fields, the problem of field name conflicts occurred very often. For the 3.0 model, thanks to the mrc_ prefix, the occurrence of field naming conflicts has been minimized to a minimum. Do not use field names that appear in the set of fixed/predefined fields.
-
for the 2.0 model, the prefix
custom_is added to the field name. Example: an object field namedstatuswill take the namecustom_status. -
for the 3.0 model, the suffix
_customis added to the field name. Example: an object field namedmrc_statuswill take the namemrc_status_custom. -
Foreign keys associated with the
Case2SubCaseentity - fields indicating the links between main (parent) and dependent (sub) cases. Such fields are built according to the following rule:- for the 2.0 model:
<field_name>_luceneDocId. Example:address_luceneDocId. - for the 3.0 model:
<field_name>_mrc_Case_id. Example:address_mrc_Case_id.
- for the 2.0 model:
Unclassified permanent fields
These are fields that are used by the internal mechanisms of the Mercury DB (HgDB) 3.0 database, but they can also be used to search for cases in Lucene index queries.
Depending on the naming model used, field names are built according to the following rules:
- for model 2.0, the field name is as is.
- for model 3.0, the prefix
mrc_is added to the field name. Example:mrc_parentTypes.
Field list:
| Field name | Description |
|---|---|
| parentFields | a string type field (String), added to the child case document, multi-valued, contains the names of the parent case fields to which it is associated. The field supports building links between indexed documents - links between main (parent) and dependent (subordinate) cases. An example of a field value is the field name: address |
| parentTypes | a string type field (String), added to the child case document, multi-valued, contains the names of the parent case types to which it is associated. The field supports building links between indexed documents - links between main (parent) and dependent (subordinate) cases. An example of a field value is the case type name: FsmService |
Lucene Index Field Types
Since the field type affects the search mechanism used by the index, an alternative concept for the field type is the concept of search type.
Basic field types (search types):
| Field Type | Description |
|---|---|
| TextField | Text field, full-text search, case insensitive. |
| StringField | Simple string field, one expression, word. Most often used to define values of the code, acronym or identifier type. Case-sensitive search. |
| LongField | Numeric field, integer, long. Searching for numbers, ranges of numbers. |
| DateField | Date field. During indexing, the value of the date field is converted to a value of milliseconds, to the type LongField. Allows to build a search range. |
| IntField | Numeric field, integer, "short". |
| FloatField | Numeric field, floating point. |
| DoubleField | Numeric field, floating point. |
| CompositeIdField | Field representing the values of the entity's composite keys. The value of such a field is converted to the StringField type. Example: the CaseDocument entity has the id field of the composite key of the CaseDocumentPK type. The value of such a field is indexed in the form: "{\"caseId\":\"" + getCaseId() + "\", \"objectId\":\"" + objectId + "\", \"versionSeriesId\":\"" + versionSeriesId + "\"}" |
| SubQuery | Composite fields to which a subcase is assigned. To use this field in the search, its name should be used as a prefix separated by a dot, e.g. address.mrc_Case_id. |
Fixed/Predefined Field Names
Fixed fields from entities representing data stored in a relational database.
TypeCode�
Lucene index field names representing the TypeCode entity. Among the types of objects stored in the system, we can distinguish documents and cases. In order to facilitate searching for objects associated with stored documents (as a document repository, as opposed to stored case objects), the c2doc component has been added to the names of the fields representing them.
List of names and meanings of individual fields associated with case objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | typeTypeCodeName [false] | mrc_typeCodeName [false] | Type code name - value representing the case type code. |
| value | StringField | typeTypeCodeValue [false] | mrc_typeCodeValue [true] | Type code value - value representing the case type code. |
List of names and meaning of individual fields related to stored document objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | c2docTypeTypeCodeName [false] | mrc_c2docTypeCodeName [false] | Type code name - value representing the type code of the stored document. |
| value | StringField | c2docTypeTypeCodeValue [false] | mrc_c2docTypeCodeValue [true] | Type code value - value representing the type code of the stored document. |
TypeKind
Lucene index field names representing the TypeKind entity. Among the types of objects stored in the system, we can distinguish documents and cases. In order to facilitate searching for objects associated with stored documents (as a document repository, as opposed to stored case objects), the c2doc component has been added to the names of the fields representing them.
List of names and meaning of individual fields associated with case objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | typeTypeKindName [false] | mrc_typeKindName [false] | Type type name - value representing the type of the case type. |
| value | StringField | typeTypeKindValue [false] | mrc_typeKindValue [true] | Type type value - value representing the type of the case type. |
List of names and meaning of individual fields related to the stored document objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | c2docTypeTypeKindName [false] | mrc_c2docTypeKindName [false] | Type type name - value representing the type of the stored document. |
| value | StringField | c2docTypeTypeKindValue [false] | mrc_c2docTypeKindValue [true] | Type type value - value representing the type of the stored type. |
TypeCase
Lucene index field names representing the TypeCase entity. The entity contains the isDocument field informing whether the given case type is a type representing document metadata or a case object. In order to facilitate searching for objects associated with stored documents (as a document repository, as opposed to stored case objects), the c2doc component has been added to the names of the fields representing them.
List of names and meaning of individual fields associated with case objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| accountNumber | StringField | typeAccountNumber [false] | mrc_typeAccountNumber [false] | Case type field, accounting number/code, predefined field, important when building production accounting and planning systems, materials management, technical documentation and other areas. |
| description | TextField | typeDescription [false] | mrc_typeDescription [false] | Case type field. Description |
| - | StringField | typeSourceOfObject [false] | mrc_typeSourceOfObject [false] | Case type field indicating the origin (source) of the case type definition. Field related to the case type, but located in the TypeCase2SourceOfObject entity |
| id | StringField | typeLuceneDocId [true] | mrc_typeTypeCase_id [true] | Case type identifier. |
| typeName | StringField | typeTypeName [false] | mrc_typeTypeName [false] | Case type name. |
List of names and meanings of individual fields related to stored document objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| accountNumber | StringField | c2docTypeAccountNumber [false] | mrc_c2docTypeAccountNumber [false] | Document type field, accounting number/code, predefined field, important when building production accounting and planning systems, materials management, technical documentation and other areas. |
| description | TextField | c2docTypeDescription [false] | mrc_c2docTypeDescription [false] | Document type field. Description |
| - | StringField | c2docTypeSourceOfObject [false] | mrc_c2docTypeSourceOfObject [false] | Document type field indicating the origin (source) of the document type definition. Most often indicates the name of an external document repository, allowing communication via the CMIS protocol. Field related to the case type, but located in the TypeCase2SourceOfObject entity |
| id | StringField | c2docTypeTypeCase_id [true] | mrc_c2docTypeTypeCase_id [true] | Document type field. |
| typeName | StringField | c2docTypeTypeName [false] | mrc_c2docTypeTypeName [false] | Document type field. type name. |
Source
Lucene index field names representing the Source entity. This entity stores information about the sources of issues and documents. These sources can be used to identify the origin of issues and documents, which is useful in the context of auditing and data management. Since we can distinguish document types and issue types, the c2doc component was added to the field names representing them to make it easier to search for documents.
List and meaning of individual fields related to issue objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | grSrcName [false] | mrc_grSrcName [false] | Issue group source name |
| value | StringField | grSrcValue [false] | mrc_grSrcValue [true] | Case group source identifier |
List and meaning of individual fields related to stored document objects
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | c2docSrcName [false] | mrc_c2docSrcName [false] | Stored document group source name |
| value | StringField | c2docSrcValue [false] | mrc_c2docSrcValue [true] | Stored document group source identifier |
Here are some sample values representing case and document sources:
value | name | description |
|---|---|---|
| SoapUI | SoapUI | Generated source from SoapUI |
| IMP_EXCEL | USER_DEV.localhost | Case imported from Excel file. |
| USER_DEV.localhost | USER_DEV.localhost | Generated source from USER_DEV.localhost |
| BPMProcessesSecretary | BPMProcessesSecretary | Generated source from BPMProcessesSecretary |
GroupCase
Lucene index field names representing the *GroupCase entity. The role of the entity is to group cases that are related to each other. A case group can be used to manage and organize cases that have common features or are part of a larger process. In production accounting and planning systems, materials management, technical documentation and other fields, a case group can define a fixed asset, resource. Therefore, this entity is associated with the KtmNumber entity, which is used to identify a fixed asset or resource.
The values of the GroupCase entity fields are generated automatically when creating a single or multiple cases. These values are unique for each case group and should not be modified manually.
List of names and meaning of individual fields
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| id | StringField | grLuceneDocId [true] | mrc_grGroupCase_id [true] | Case group identifier. |
Case
Lucene index field names representing the Case entity. The main entity storing case data. Depending on the naming model used, the mrc_ prefix is added to the basic entity field names for the 3.0 model. Most of the predefined Case entity fields have a business role aimed at use in production accounting and planning systems, materials management, technical documentation, and other areas.
List of names and meanings of individual fields
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| id | StringField | luceneDocId [true] | mrc_Case_id [true] | Unique case/document identifier |
| bpmProcessId | LongField | bpmProcessId [true] | mrc_bpmProcessId [true] | BPM process instance identifier, identifier from external system e.g. IBM BPM |
| bpmProcessId | StringField | bpmProcessIdNotNull [false] | mrc_bpmProcessIdNotNull [false] | Additional index field allowing searching for cases that are not associated with a BPM process instance. |
| createDate | LongField | createDate [true] | mrc_createDate [true] | Date of creation |
| createdBy | StringField | createdBy [true] | mrc_createdBy [true] | Name of the user who created the case |
| createdByRoleName | StringField | createdByRoleName [true] | mrc_createdByRoleName [true] | Name of the role of the user who created the case |
| dueDate | LongField | dueDate [true] | mrc_dueDate [true] | BPM process instance data: due date. |
| endDate | LongField | endDate [true] | mrc_endDate [true] | BPM process instance data: process instance end date, case processing end date. |
| lastModifedBy | StringField | lastModifedBy [false] | mrc_lastModifedBy [false] | Username modifying the case |
| lastModifiedByRoleName | StringField | lastModifiedByRoleName [false] | mrc_lastModifiedByRoleName [false] | Role name of the user modifying the case |
| lastModifyDate | LongField | lastModifyDate [true] | mrc_lastModifyDate [true] | Date the case was modified |
| piervousVersionId | StringField | piervousVersionId [true] | mrc_piervousVersionId [true] | An identifier pointing to the previous version of the case |
| rootVersionId | StringField | rootVersionId [true] | mrc_rootVersionId [true] | Identifier indicating the main, first version of the case |
| inventoryCode | StringField | inventoryCode [true] | mrc_inventoryCode [true] | Inventory code - a predefined field for using the system as a fixed assets database. |
| inventoryCode | StringField | inventoryCodeReverse [false] | mrc_inventoryCodeReverse [false] | Additional index field, the value of which is the reverse of the inventoryCode field value. Example: when the inventoryCode field has the value "4/G/1231234" , the field value will be "4321321/G/4". |
| priceValue | DoubleField | priceValue [true] | mrc_priceValue [true] | Monetary value of the case - a predefined field for using the system as a fixed assets database |
| - | DoubleField | priceValueSys [false] | mrc_priceValueSys [false] | Monetary value of the case converted to the system currency Mercury DB (HgDB) 3.0 - system currency is configurable |
| priceValueCode | StringField | priceValueCode [false] | mrc_priceValueCode [false] | Currency code corresponding to the monetary value of the case, e.g. EUR, PLN, $ - a predefined field for using the system as a fixed assets database. |
| priceExchangeDate | DoubleField | priceExchangeDate [false] | mrc_priceExchangeDate [false] | date of currency exchange, conversion of the monetary value of the case to the system currency. |
| status | StringField | status [false] | mrc_status [false] | Status of the case3, allowed values: A, O, N, Z |
| - | TextField | luceneDocumentMemo [false] | mrc_luceneDocumentMemo [false] | A text field composed of the values of most of the case fields. Its purpose is to allow searching for cases without having to specify the name of the field representing the search value. |
Comment
Lucene index field names representing the Comment entity, which stores comments associated with case objects. Comments can be added to cases, documents, or other objects in the system. For information on how to add comments to issues, see Comments to issues.
List of field names and meanings
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| id | StringField | commLuceneDocId [true] | mrc_commComment_id [true] | Comment ID |
| content | TextField | commContent [false] | mrc_commContent [false] | Comment content |
| username | StringField | commUsername [false] | mrc_commUsername [false] | Username who added the comment |
QuickTask
Lucene index field names representing the QuickTask2 entity. As the name suggests, this entity stores data about quick tasks associated with cases. Quick tasks can be added to cases, documents, or other objects in the system. You can read about how to add quick tasks to cases in the Quick Tasks article.
List of field names and meanings
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| description | TextField | qtDescription [false] | mrc_qtDescription [false] | Task description. |
| from | StringField | qtFrom [false] | mrc_qtFrom [false] | Task sender, information about who the task is from. |
| priority | StringField | qtPriority [false] | mrc_qtPriority [false] | Task priority |
| id | StringField | qtLuceneDocId [true] | mrc_qtQuickTask_id [true] | Unique task identifier. |
| replyDate | LongField | qtReplyDate [false] | mrc_qtReplyDate [false] | Reply date |
| replyText | TextField | qtReplyText [false] | mrc_qtReplyText [false] | Reply comment, description of steps taken to complete the task. |
| sendDate | LongField | qtSendDate [false] | mrc_qtSendDate [false] | Date the task was sent |
| to | StringField | qtTo [false] | mrc_qtTo [false] | Task recipient, to whom the task is sent. |
CaseDocument
Lucene index field names representing the CaseDocument entity. This entity stores data about documents related to cases, which are stored in an external document repository.
List of names and meaning of individual fields
| Entity Field Name | Search Type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| id | CompositeIdField | c2docLuceneDocId [false] | mrc_c2docCaseDocument_id [false] | Representation of the document identifier, which is a composite key. The field value takes the form: {\"caseId\":\"" + id.caseObj.id + "\", \"objectId\":\"" + id.objectId + "\", \"versionSeriesId\":\"" + id.versionSeriesId + "\"} |
| id.caseObj.id | LongField | c2docCaseId [false] | mrc_c2docCaseId [false] | The field represents the value of the case identifier to which the given document has been associated (a component of the foreign key id ). |
| id.objectId | StringField | c2docObjectId [false] | mrc_c2docObjectId [false] | The document object identifier in the external document repository. |
| id.versionSeriesId | StringField | c2docVersionSeriesId [false] | mrc_c2docVersionSeriesId [false] | The field represents the document version value (a component of the foreign key id ). the document version identifier in the external document repository. |
| author | TextField | c2docAuthor [false] | mrc_c2docAuthor [false] | The author description of the document. |
| contentStreamId | StringField | c2docContentStreamId [false] | mrc_c2docContentStreamId [false] | Document stream identifier in external document repository. |
| groupingCode | StringField | c2docGroupingCode [false] | mrc_c2docGroupingCode [false] | Code grouping a collection of documents |
| isInput | StringField | c2docIsInput [false] | mrc_c2docIsInput [false] | - |
| isRoot | StringField | c2docIsRoot [false] | mrc_c2docIsRoot [false] | - |
| receivedDate | LongField | c2docReceivedDate [false] | mrc_c2docReceivedDate [false] | Date sent |
| receiver | TextField | c2docReceiver [false] | mrc_c2docReceiver [false] | Sender |
| receiverDW | TextField | c2docReceiverDW [false] | mrc_c2docReceiverDW [false] | Carbon Copy of message (CC). In polish version this is Do wiadomości (DW) |
| subject | TextField | c2docSubject [false] | mrc_c2docSubject [false] | Document subject |
| versionLabel | StringField | c2docVersionLabel [false] | mrc_c2docVersionLabel [false] | Document version label. |
Participant
Lucene index field names representing the Participant entity, which is a predefined entity in the Mercury DB (HgDB) 3.0 system. It is important when building production planning and accounting systems, materials management, technical documentation and other areas.
A Participant is a person who jointly bears the costs of some undertaking with someone else or has a share in the profits from some undertaking. In the Mercury DB (HgDB) 3.0 system, a case participant can be a client, applicant, participant in the case who is associated with a given case. Based on the kind field, which specifies their role in the case, three types of participants are distinguished: Client, Applicant and Participant. In order to obtain the relationship between the individual types of applicant and cases, the appropriate names of Lucene index fields were used.
List of names and meanings of individual fields for Client participants
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| contactPerson | TextField | grClientContactPerson [false] | mrc_grClientContactPerson [false] | - |
| StringField | grClientEmail [false] | mrc_grClientEmail [false] | - | |
| fullname | TextField | grClientFullname [false] | mrc_grClientFullname [false] | - |
| identity | StringField | grClientIdentity [false] | mrc_grClientIdentity [false] | - |
| - | TextField | grClientKindName [false] | mrc_grClientKindName [false] | - |
| id | StringField | grClientLuceneDocId [true] | mrc_grClientParticipant_id [true] | - |
| participantName | TextField | grClientParticipantName [false] | mrc_grClientParticipantName [false] | - |
| phone1 | StringField | grClientPhone1 [false] | mrc_grClientPhone1 [false] | - |
| phone2 | StringField | grClientPhone2 [false] | mrc_grClientPhone2 [false] | - |
List of names and meanings of individual fields for Applicant participants
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| contactPerson | TextField | grApplicantContactPerson [false] | mrc_grApplicantContactPerson [false] | - |
| StringField | grApplicantEmail [false] | mrc_grApplicantEmail [false] | - | |
| fullname | TextField | grApplicantFullname [false] | mrc_grApplicantFullname [false] | - |
| identity | StringField | grApplicantIdentity [false] | mrc_grApplicantIdentity [false] | - |
| - | TextField | grApplicantKindName [false] | mrc_grApplicantKindName [false] | - |
| id | StringField | grApplicantLuceneDocId [true] | mrc_grApplicantParticipant_id [true] | - |
| participantName | TextField | grApplicantParticipantName [false] | mrc_grApplicantParticipantName [false] | - |
| phone1 | StringField | grApplicantPhone1 [false] | mrc_grApplicantPhone1 [false] | - |
| phone2 | StringField | grApplicantPhone2 [false] | mrc_grApplicantPhone2 [false] | - |
List of names and meanings of individual fields for participants Participant
| Entity Field Name | Search Type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| contactPerson | TextField | grParticipantContactPerson [false] | mrc_grParticipantContactPerson [false] | - |
| StringField | grParticipantEmail [false] | mrc_grParticipantEmail [false] | - | |
| fullname | TextField | grParticipantFullname [false] | mrc_grParticipantFullname [false] | - |
| identity | StringField | grParticipantIdentity [false] | mrc_grParticipantIdentity [false] | - |
| - | TextField | grParticipantKindName [false] | mrc_grParticipantKindName [false] | - |
| id | StringField | grParticipantLuceneDocId [true] | mrc_grParticipantParticipant_id [true] | - |
| participantName | TextField | grParticipantParticipantName [false] | mrc_grParticipantParticipantName [false] | - |
| phone1 | StringField | grParticipantPhone1 [false] | mrc_grParticipantPhone1 [false] | - |
| phone2 | StringField | grParticipantPhone2 [false] | mrc_grParticipantPhone2 [false] | - |
KtmNumber
Lucene index field names representing the KtmNumber1 entity. The entity is used to store information about KTM (Product-Material Code) codes associated with a group of cases (GroupCase) representing a fixed asset. KTM codes are used to identify and classify goods and materials. KtmNumber is a predefined entity in the Mercury DB (HgDB) 3.0 system. It is important when building production accounting and planning systems, materials management, technical documentation and other areas.
List of names and meanings of individual fields
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| description | TextField | grKtmDescription [false] | mrc_grKtmDescription [false] | Code description, description of the fixed asset represented by the code. |
| groupCode | StringField | grKtmGroupCode [false] | mrc_grKtmGroupCode [false] | Case group code. |
| ktmCode | StringField | grKtmKtmCode [false] | mrc_grKtmKtmCode [false] | Code. |
| id | StringField | grKtmLuceneDocId [true] | mrc_grKtmKtmNumber_id [true] | KTM code identifier. |
| priceValue | DoubleField | grKtmPriceValue [false] | mrc_grKtmPriceValue [false] | Fixed asset value represented by the code. |
InitStatus
Lucene index field names representing the InitStatus entity. This entity is used to store information about the initial status of the document associated with the case. This status can be used to determine the status of the document at the beginning of its workflow.
List of names and meaning of individual fields
| Entity field name | Search type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|---|
| name | TextField | c2docInitStatName [false] | mrc_c2docInitStatName [false] | - |
| value | StringField | c2docInitStatValue [false] | mrc_c2docInitStatValue [false] | - |
Case2SubCase
The Lucene index field names representing the Case2SubCase entity.
List of field names and meanings
| Search Type | Model 2.0 [sorting] | Model 3.0 [sorting] | Description |
|---|---|---|---|
| StringField | parentFields [false] | mrc_parentFields [false] | Multi-valued field, list of field names where the case appears as a child case. |
| LongField | dynamic name in the form <field_name>LuceneDocId [false] | dynamic name in the form <field_name>_mrc_Case_id [false] | Child case identifier, where <field_name> is the name of the field that represents it in the parent case. Multi-valued field when a list of cases is associated with the given field. |
Predefined complex field types
It is possible to define a field of type "COMPLEX" indicating the implementation of the class that represented such a field. Currently, Mercury 3.0 (Hgdb) has built-in support for two classes. They are important when building production planning and accounting systems, materials management, technical documentation, and other areas.
CaseClient
Lucene index field names representing the pro.ibpm.mercury.values.beans.CaseClient class.
List of names and meaning of individual fields
| Entity field name | Search type | Name [sorting] | Description |
|---|---|---|---|
| clientType | StringField | caseclientClientType [false] | Client type |
| companyName | TextField | caseclientCompanyName [false] | Name of the company represented by the client |
| contactPerson | TextField | caseclientContactPerson [false] | Client contact person |
| StringField | caseclientEmail [false] | Email address | |
| name | TextField | caseclientName [false] | Name |
| pesel | StringField | caseclientPesel [false] | Mandatory customer identifier, e.g. one of the values representing the customer: REGON4, PESEL5 or NIP6.You can use the IDs used in your country. |
| phoneNumber1 | StringField | caseclientPhoneNumber1 [false] | Contact, phone number 1 |
| phoneNumber2 | StringField | caseclientPhoneNumber2 [false] | Contact, phone number 2 |
| regon | StringField | caseclientRegon [false] | Optional value, REGON3 |
| surname | TextField | caseclientSurname [false] | Surname, name extending the customer name |
CaseApplicant
Lucene index field names representing the pro.ibpm.mercury.values.beans.CaseApplicant class.
List of names and meaning of individual fields
| Entity field name | Search type | Name [sorting] | Description |
|---|---|---|---|
| agentNumber | StringField | caseapplicantAgentNumber [false] | Agent number, agent identifier |
| applicantType | StringField | caseapplicantApplicantType [false] | Agent type |
| brokerName | TextField | caseapplicantBrokerName [false] | Insurance broker/agency name |
| workerName | TextField | caseapplicantWorkerName [false] | Employee/agent common name |
Footnotes
-
Commodity and Material Code (KTM) - a set of symbols and other information identifying goods in circulation or materials in records, applicable in contacts between suppliers and recipients, in correspondence and in documents of goods and materials circulation. KTM is also used in production records and planning, materials management, technical documentation and in other areas. It is particularly important in creating material, product and product indexes (edited by I. Duda 1994, p. 71). Material indexes are systematic lists of materials containing the name and closer definition of the material, unit of measurement, other material features important from the point of view of records and digital symbols. In enterprises, industry material indexes may be used, containing materials typical for a given industry, and plant indexes - for materials used only in a specific enterprise. Material indexes enable mechanization of records and activities related to planning, reporting and control of material consumption (D. Dębski 2006, p. 85). In international trade, a type of such code is GTIN. Source: Wikipedia. ↩ ↩2
-
Quick Task represents a one-time action related to a case but not related to a workflow. Case workers can create quick tasks for a case type to help them stay organized and complete unexpected or one-time tasks. For example, suppose a case worker recognizes that a follow-up call to a customer is necessary. The case worker creates a quick task to document this need. The case worker can then assign the quick task to another case worker and set a deadline for completion. Quick tasks appear in the To-do list with checklist widget. A case worker can create a quick task by simply entering its name. Once the task is created, the case worker can add a description, assign the task, and set a deadline for completion. A quick task is marked as closed by clicking it once in the To-do list with checklist widget. Source: IBM Documentation. ↩ ↩2
-
Case status is a predefined field that can be used to indicate the status of the case. Allowed values are:
A(active),O(open),N(inactive),Z(closed). The field value is used to filter cases in the user interface and when searching for cases in the Lucene index. ↩ ↩2 -
REGON (National Economy Register), National Official Register of National Economy Entities - a register kept by the President of the Central Statistical Office. The term REGON also refers to the REGON identification number, which is a nine-digit identifier assigned to an entity in this register. Source: Wikipedia. ↩
-
PESEL – Universal Electronic Population Registration System – a central database maintained in Poland by the minister responsible for computerization (until the end of 2015 by the minister responsible for internal affairs) under the Population Registration Act. The register is used to collect basic information identifying the identity and administrative and legal status of Polish citizens and foreigners residing in the territory of the Republic of Poland. Colloquially, the PESEL is also referred to as the registration number of a natural person used in this register. Source: Wikipedia. ↩
-
NIP - Tax Identification Number - a ten-digit code used to identify taxpayers in Poland. It was introduced by the act of October 1995, and came into force in 1996. It is assigned by the head of the tax office. Since September 1, 2011, individuals who do not run a business use the PESEL number as a tax identifier. Source: Wikipedia. ↩