System architecture
Mercury DB (HgDB) 3.0 is an implementation of an object database service server based on the relational SQL model (data is stored in relational structures). This allows the use of all solutions related to the object orientation that is ubiquitous in modern systems and traditional BI (Business Intelligence) systems based on a relational engine.
Mercury DB (HgDB) 3.0 system layers
A number of layers have been defined in the product, among which the following should be distinguished.
- Core – a set of internal mechanisms, abstractions and implementations describing data definitions (ENTITY model), their dependencies and flows, sets of interfaces describing actions on data.
- DAO – data access layer. Implementations of data persistence mechanisms in a relational database, the engine of which can be PostgreSQL, MySQL, Oracle, DB2 and others.
- Logic – object processing layer. Implementations of operations on objects representing entities. At the logical layer level, the world of the relational database is combined with the search in the Lucene index.
- Business – an object processing layer operating on objects from the external world. In this layer, any object is transformed into model objects that allow it to be stored in the Mercury DB (HgDB) database.
SOAP and REST services are exposed at the level of two layers:
- API Logic – services operating on entity objects. To use these services, you need to be aware of the format in which the data is stored. You need to know the dependencies between entities to ensure their consistency. You need to know how to define a case type, what parameters can be set for it, what data is control data. You need to know how simple types are defined, how they are represented in the appropriate HTML controls when generating dynamic data editing forms. Services are used, for example, to create GUI applications for presentations stored in the database or for additional configuration of collected types, such as supplementing the type definition with dictionary values, authorizations for individual fields, linking type fields with alternative names.
- API Business – services operating on case objects. No detailed knowledge of how data is stored is required. No detailed knowledge of how to define the type of object is required. Business layer mechanisms try to ensure data consistency, automatically identify external objects, categorize and save in the appropriate form. Of course, you need to know a few rules that determine optimal data collection.
Cluster architecture
All components of the Mercury DB (HgDB) 3.0 system are interconnected and cooperate in a distributed mode. Cluster nodes can be installed on different servers, and their number can be any. Cluster nodes can be installed on different servers, and their number can be any. Cluster nodes can be installed on different servers, and their number can be any.
The diagram shows how the system components are connected in a cluster configuration.
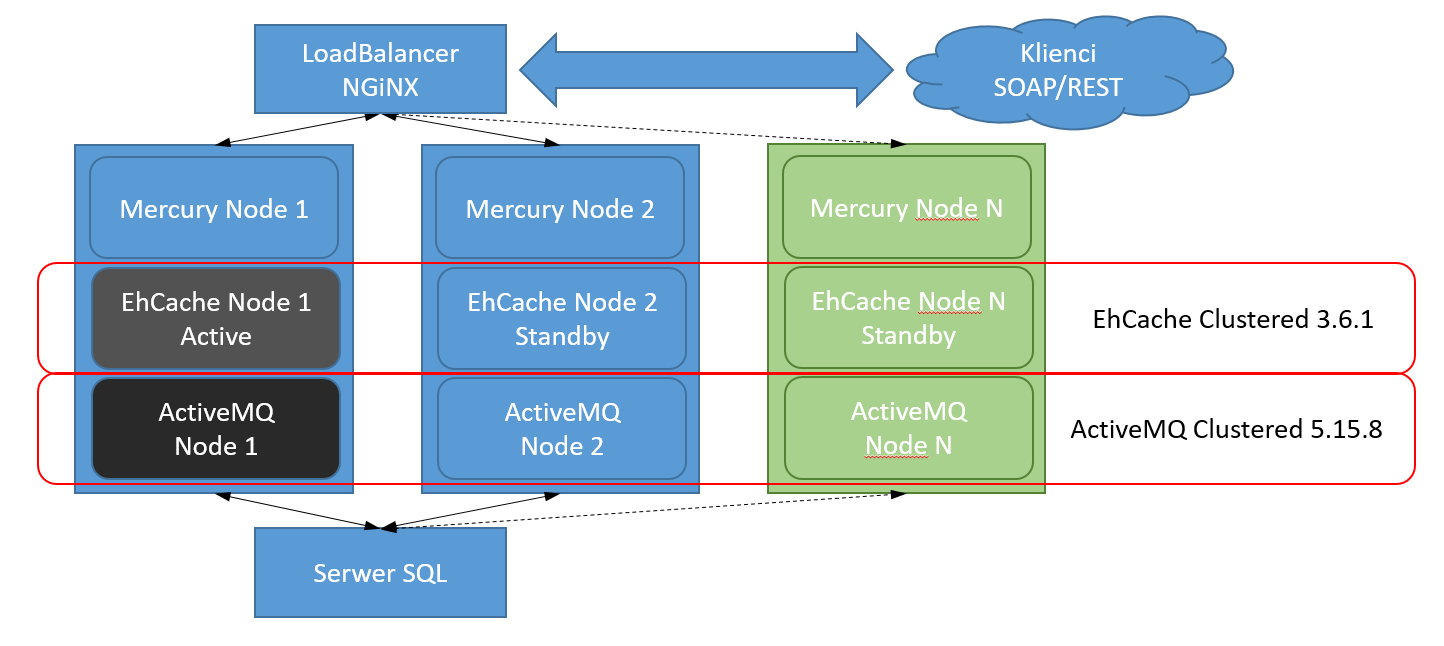
LoadBalancer
NGINX was selected as the load balancing application between cluster nodes.
NGINX is a web server, HTTP proxy server, IMAP/POP3/SMTP proxy server and TCP/UDP proxy server. It is an open source software that can be used as a web server, HTTP proxy server, IMAP/POP3/SMTP proxy server and TCP/UDP proxy server. NGINX is known for its high performance and low resource consumption.
To summarize:
- NGINX - designed for high availability and heavily loaded services (emphasis on scalability and low resource occupancy). It is released under the BSD license.
- According to Netcraft's June 2016 report, the NGiNX server was used by over 169 million domains, which ranks it third among WWW servers; in June 2018, NGiNX was used by 18.45% of all registered Polish domains.
- Simple configuration.
- It is recommended to install NGiNX on separate servers.
EhCache Clustered
A shared memory Clustered Cache based on the Terracotta server was used to handle the cache in the cluster architecture.
- EhCache is a distributed Java cache for storing and general caching of Java EE objects. EhCache is available under the Open Source Apache 2.0 license.
- Possibility of configuring an HA cluster – one of the nodes is always active, the rest work in standby mode.
- Each service server node uses its local cache. The EhCache server is used to synchronize data between individual cluster members.
- Used by the Hibernate framework to manage entities (data stored in a relational database).
Apache ActiveMQ
Apache ActiveMQ was used to handle events and communicate between cluster nodes.
- Apache ActiveMQ ™ is the most popular and efficient Open Source server for handling message queues.
- Apache ActiveMQ is fast, supports multiple clients and protocols of various programming languages. It is equipped with easy-to-use integration patterns and has many advanced features. It fully supports JMS 1.1 and J2EE 1.4 standards. Apache ActiveMQ is released under the Open Source Apache 2.0 license.
- In the Mercury DB (HgDB) 3.0 cluster, the communication queue server is used to exchange data between individual cluster members. Examples of messages include a heartbeat transmitting data about the status of a single node, a message informing about the need to refresh caches, or a message invoking the document indexing operation after the data update task has been performed by one of the cluster nodes.
SQL Server
The SQL server is responsible for persisting data. Stored in the relational database, they are used to build the Lucene index, which is used to search for data in the system. The SQL server is responsible for storing object data and their metadata.
- The following products can act as the SQL server: Oracle, MySQL, PostgreSQL, DB2, MSSQL.
- Each of the Mercury DB (HgDB) 3.0 relational engine services supported by the server has its own support for cluster architecture.
Integration with Iron POI Excel Server
Iron - POI Excel Server is a server of services supporting reading files in MS Excel format (*.xlsx) for the needs of process applications created using the IBM BPM tool (IBM Business Process Manager). Implementation based on Apache POI (Poor Obfuscation Implementation) libraries, among others.
The main role of Mercury DB (HgDB) 3.0 integration with Iron POI Excel Server is the ability to operate on Excel files via REST API services. Thanks to this, it is possible to:
- Load data from Excel files to the database
- Export data to Excel files
IRON Poi Server is integrated with JasperReports®Library libraries. The available desktop tool Jaspersoft®Studio allows for quick creation and editing of report templates in various formats. The whole allows for:
- Easy building of document templates, which are the basis for reporting.
- Report generation in file formats:
*.docx(Word document),*.xlsx(Excel document),*.pdf(PDF document) and others…
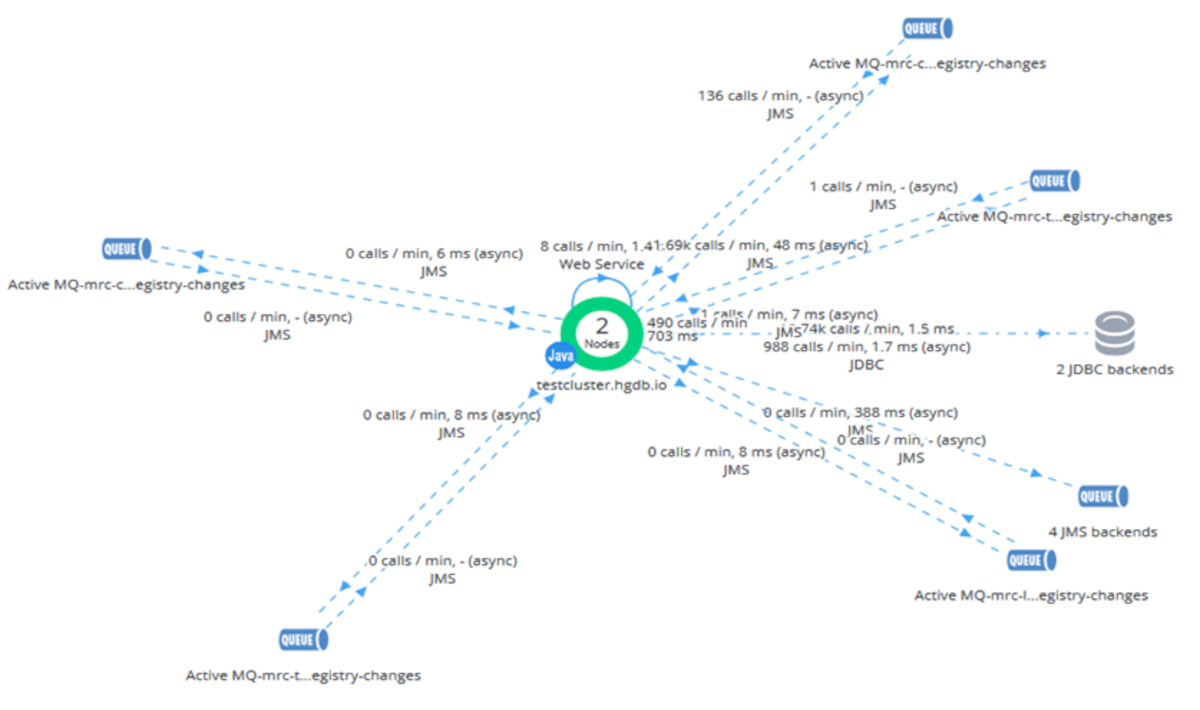
Cluster flow map
Below is a data flow map prepared based on the AppDynamics monitoring tool. The illustration shows the work of two cluster nodes.
Other elements of the Mercury DB (HgDB) architecture
The description of the Mercury DB (HgDB) 3.0 structure has been divided into several sections. Each of them presents a detailed description of the elements and their use in the system.
📄️ Case metadata
Mercury is a repository of metadata about objects along with definitions of GUI controls enabling the generation of GUI forms. Metadata is structured information used to describe objects (cases) - it describes the logical and physical relationship between parts of a complex object (see Describing digital objects, October 21, 2016 [accessed 2020-07-01]). Mercury DB in its structures also allows for storing the necessary data allowing for the generation of edit forms and presentation pages of stored objects. Metadata is stored in a relational database (SQL). A synonym for the definition of case metadata is the case type. Below is a description of the entity.
📄️ Case versioning
When updating case objects, the change history is automatically created. However, when the case type changes, which is often the case in rapidly developing systems that change the data storage model, a new version of the case is created. The action occurs automatically when (using business layer services) we save the case (existing) and when a type change is detected, i.e. a new field is added, a field type change is detected. Since version 3.0.1.0.2, the version change action can be performed "manually" by invoking the appropriate sequence of saves, which we will discuss at the end of the article.
📄️ Index Lucene
The basis for searching in the Mercury DB system is the [Lucene] Index (https://lucene.apache.org). This article will present the principles of creating field names, which are the basis for implementing search queries. It will also present the division of fields according to their type, category (division according to field origin) and search method (division according to field type).
📄️ Permissions mechanism
Mechanism of dependencies between objects and access roles to objects in the Mercury DB system. The assumption is to meet the requirement that the system has an advanced mechanism for managing user permissions to perform operations on individual types of cases with granulation of permissions to individual fields of case objects.